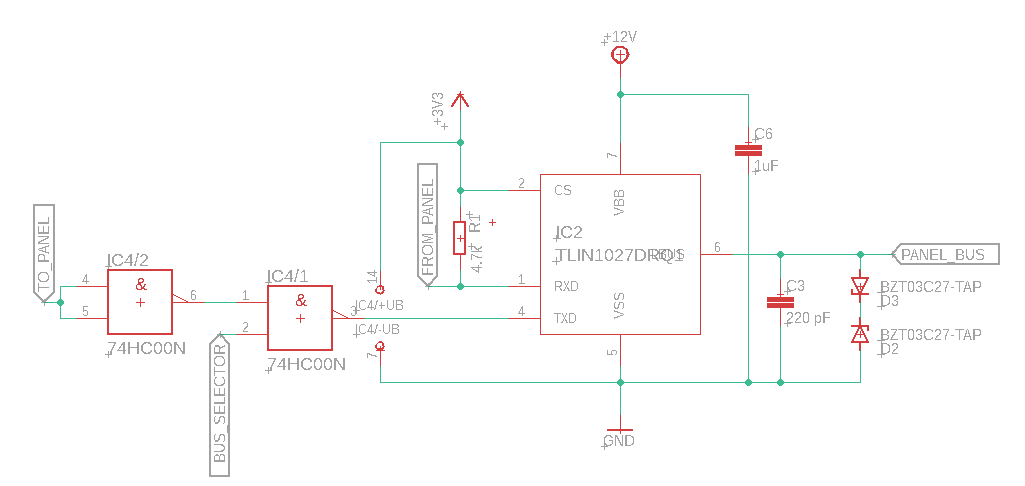
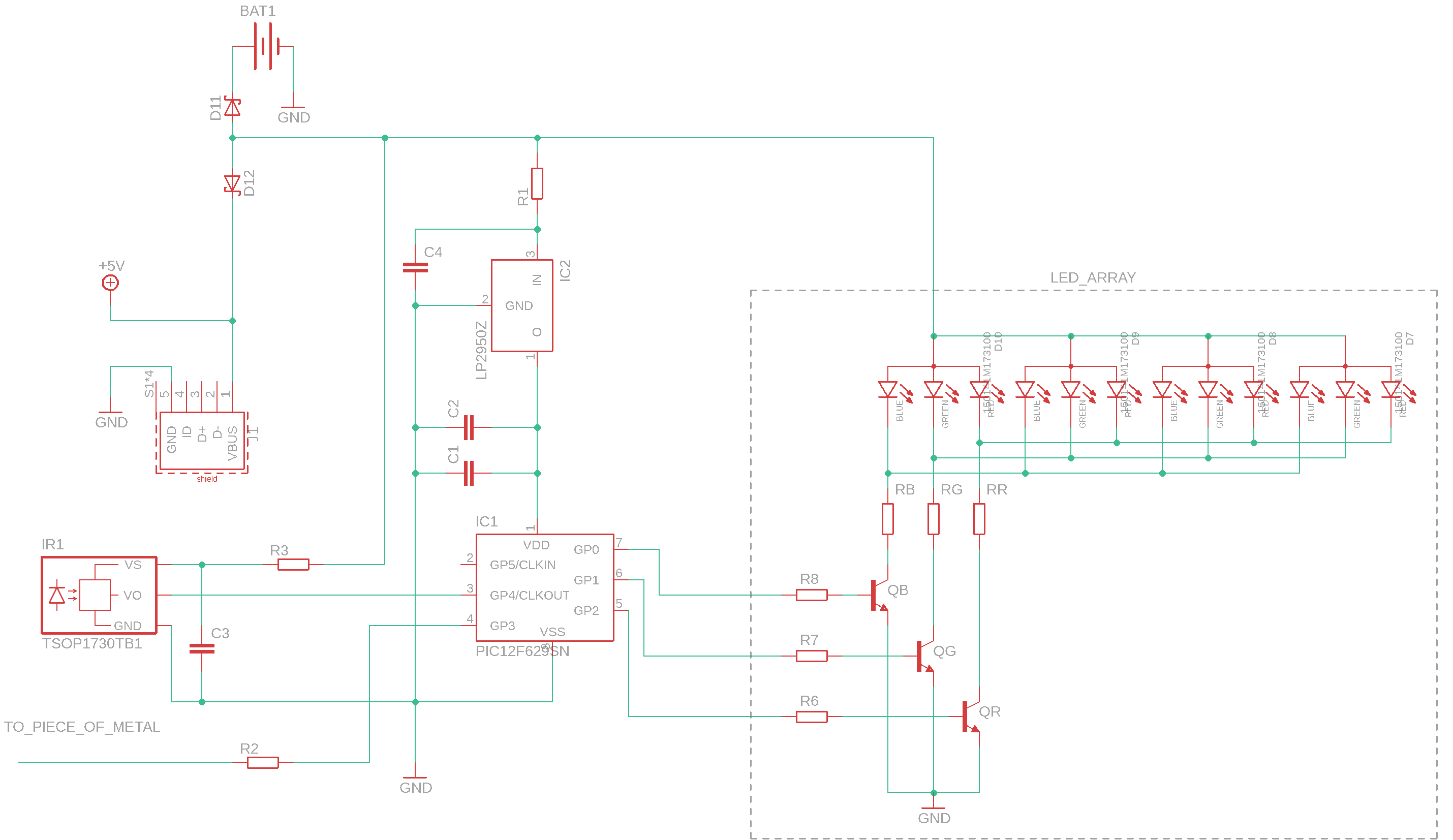
English Technical2021-08-03 Reverse Engineering an LG Aircon Control Panel — Fit It All Together Flameeyes
English Technical2021-07-13 Reverse Engineering an LG Aircon Control Panel — Low-Speed Serial Issues Flameeyes
English Technical2021-06-29 Reverse Engineering an LG Aircon Control Panel — Buses and Cars Flameeyes