Flameeyes's Weblog
This Time Self-Hosted
dark mode
light mode
Search
Flameeyes's Weblog
Search
Search
Popular tags
Gentoo
xine
Ruby
KDE
Security
Peregrinazioni Mentali
Tinderbox
FreeBSD
Hardware
Meta
The Latest
View All
2026-07-03
No comments
Identity Crisis In The Age of AI
2026-06-19
No comments
Bloke On A Trike
2026-05-22
No comments
This Blog, Brought To You Through AI! (Well, Kinda)
2026-05-08
2 comments
Did I Finally Solve My Audiobook Woes? Well, Maybe.
Browsing Tag
OpenOffice
18 posts
English
Personal
Technical
2010-02-11
OpenOffice trouble, again, again, again
Flameeyes
English
Personal
2010-02-10
I do support FSFE… it’s positive!
Flameeyes
English
Technical
2010-01-13
(Mis)feature by (mis)feature porting
Flameeyes
English
Personal
Technical
2009-12-06
Why natural language interfaces suck
Flameeyes
English
Technical
2009-10-12
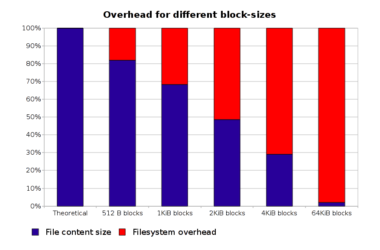
And finally, the Portage Tree overhead data
Flameeyes
English
Technical
2009-10-04
Charting and Graphing
Flameeyes
English
Technical
2009-09-28
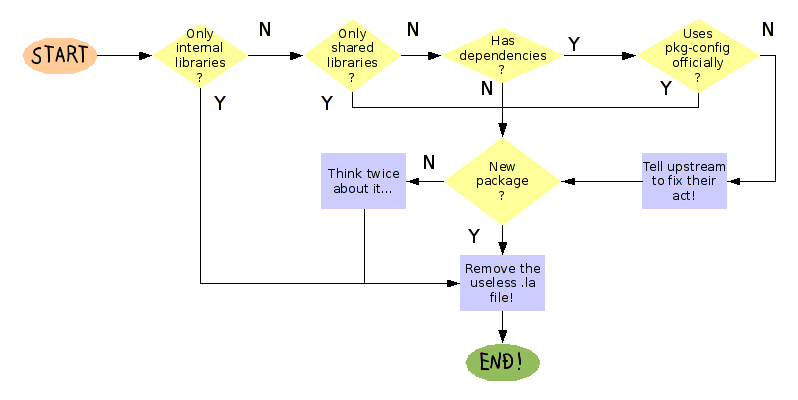
Removing .la files, for dum^W uncertain people
Flameeyes
English
Personal
Technical
2009-09-23
Who Pays the Price of Pirated Programs
Flameeyes
English
Technical
2008-11-27
Inconsistent Scalable Vector Graphics
Flameeyes
English
Personal
2008-11-12
Working with .NET, OpenOffice, and Mono
Flameeyes