As a Free Software developer, and one that has worked in a number of separate projects as well as as totally different lines of work, I find myself having nuance and varied opinions on a bunch of topics, which sometimes don’t quite fit into the “common knowledge” shared on videos, blog posts or even university courses.
One such opinion relates to testing software in general. I have written lots about it, and I have ranted about it more recently as I was investigating a crash in unpaper live on-stream. Testing is undoubtedly one of the most useful techniques for developers and software engineers to build “properly solid” software. It’s also a technique that, despite a lot of writing about it, I find is nearly impossible to properly teach without first hand experience.
I want to start this by staying that I don’t believe there is an universal truth about testing. I don’t think I know everything there is to know about testing, and I speak almost exclusively from experience — experience that I acquired in now over ten years working in different spaces within the same industry, in sometimes less than optimal ways, and that has convinced me at times that I held the Truth (with capital T), just to crush my expectations a few months later.
So the first thing that I want you all to know, if you intend on starting down the path of caring more about testing, is to be flexible. Unless your job is literally responsible for someone’s life (medical, safety, self-driving), testing is not a goal in and by itself. It rather is a mean to an end: building something to be reliable. If you’re working on corporate project, your employer is much less likely to care that your code is formally verifiable, and more likely to care that your software is as bug-free as possible so that they can reap the benefits of ongoing revenue without incurring into maintenance costs.
An aside here: I have heard a few too many times people “joking” about the fact that proprietary, commercial software developers introduce bugs intentionally so that they can sell you an update. I don’t believe this is the case, not just because I worked for at least a couple of those, but most importantly because a software that doesn’t include bugs generally make them more money. It’s easier to sell new features (or a re-skinned UI) — or sometimes not even that, but just keep changing the name of the software.
In the Free Software world, testing and correctness are often praised, and since you don’t have to deal with product managers and products overall, it sounds like this shouldn’t be an issue — but the kernel of truth there is that there’s still a tradeoff to be had. If you take tests as a dogmatic “they need to be there and they need to be complete”, then you will eventually end up with a very well tested codebase that is too slow to change when the environment around it changes. Or maybe you’ll end up with maintainers that are too tired to deal with it at all. Or maybe you’ll self-select for developers who think that any problem caused by the software is actually a mistake in the way it’s used, since the tests wouldn’t lie. Again, this is not a certainty, but it’s a chance it can happen.
With this in mind, let me go down the route of explaining what I find important in testing overall.
Premise and preambles
I’m going to describe what I refer to as the layers of testing. Before I do that, I want you to understand the premise of layering tests. As I said above, my point of view is that testing is a technique to build safe, reliable systems. But, whether you consider it in salary (and thus hard cash) in businesses or time (thus “indirect” cash) in FLOSS projects, testing has a cost, and nobody really wants to build something safely in an expensive way, unless they’re doing it for fun or for the art.
Since performative software engineering is not my cup of tea, and my experience is almost exclusively in “industry” (rather than “academic”) setting, I’m going to ignore the case where you want to spend as much time as possible to do something for the sake of doing something, and instead expect that if you’re reading further, you’re interested in the underlying assumption that any technique that helps is meant to help you produce something “more cheaply” — that is the same premise as most Computer-Aided Software Engineering tools out there.
Some of the costs I’m about to talk about are priced in hard cash, other are a bit more vacuous — this is particularly the case at the two extremes of the scale: small amateur FLOSS projects rarely end up paying for tools or services (particularly when they are proprietary), so they don’t have a budget to worry about. In a similar fashion, when you’re working for a huge multinational corporation that literally design their own servers, it’s unlikely that testing end up having a visible monetary cost to the engineers. So I’ll try to explain, but you might find that the metrics I’m describing make no sense to you. If so, I apologize, and might try harder next time, feel free to let me know in a comment.
I’m adding another assumption here: testing is a technique that allows changes to be shipped safely. We want to ship faster, because time is money, and we want to do it while wasting as little resources as possible. These are going to be keywords I’m going to refer back to a few times, and I’m choosing them carefully — my current and former colleagues are probably understanding well how these fit together, but none of these are specific of an environment.
Changes might take a lot of different forms: it might be a change to the code of an application (patch, diff, changelist, …) that needs to be integrated (submitted, merged, landed, …), or it might be a new build of an application, with a new compiler, or new settings, or new dependencies, or it might be a change in the environment of the application. Because of this, shipping also takes a lot of different shapes: you may use it to refer of publishing your change to your own branch of a repository, to the main repository, to a source release, or directly to users.
Speed is also relative, because it depends on what the change is about and what to we mean with shipping. If you’re talking about the time it take you to publish your proposed change, you wouldn’t want to consider a couple of days as a valid answer — but if you’re talking about delivering a new firmware version to all of your users, you may accept even a week’s delay as long as it’s done safely. And that goes similar to cost (since it’s sometimes the same as time): you wouldn’t consider hiring a QA person to test each patch you write for a week — but it makes more sense if you have a whole new version of a complex application.
Stages and Layers
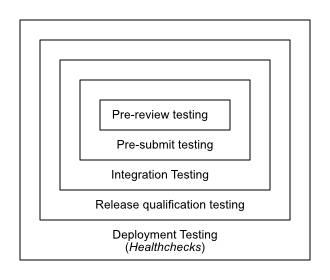
Testing has layers, like onions and orcs, and that these layers are a direct result of the number of different definitions we can attach to the same set of words, in my experience. A rough way to look at it is to consider the (rough) stages that are involved in most complex software projects: someone makes a change to the source code, someone else reviews it, it gets integrated into the project’s source code, then a person that might be one of the two already involved decides to call for a new release cut, and they eventually deliver it to their users. At each of these stages, there’s testing involved, and it’s always slightly different, both in terms of what it does, and what the tradeoffs that are considered acceptable.
I just want to publish my patch!
The first, innermost layer, I think of when it comes to testing is the testing involved in me being able to publish my change — sometimes also referred to as sending it for review. Code review is another useful technique if used well, but I would posit it’s only useful if it focuses on discussing approaches, techniques, design, and so on – rather than style and nitpicks – which also means I would want to be able to send changes for discussion early: the cost of rejecting a sub-optimal change, or at least requesting further edits to it, is proportional to the amount of time you need to spend to get the change out for review.
So what you want at this stage is fast, cheap tests that don’t require specific resources to be ran. This is the place of type-checking tools, linters, and pure, limited unit tests: tests that take a specific input, and expect the output to be either always the same or within well-established parameters. This is also where my first stone in the shoe needs to drop.
The term “change-detector test” is not widely used in public discourse, but it was a handy shorthand in my previous bubble. It refers to tests written in a way that is so tightly coupled with the original function, that you cannot change the original function (even maintaining the API contract) without changing the test. These are an antipattern for most cases — there’s a few cases in which you _really_ want to make sure that if you change anything in the implementation, you go and change the test and explicitly state that you’re okay with changing the measured approach, such as if you mean to have a constant-time calculation.
There are also the all-mocks tests — I have seen these in Python for the most part, but they are not exclusive to it, since any language that has easy mocking and patching facilities can lead to this outcome — and for languages that lack those, overactive dependency injection can give similar results. These tests are set up in such a way that, no matter what the implementation of the interface under test is, it’s going to return you exactly what you set up in the mocks. They are, in my experience, a general waste of time, because they add nothing over not testing the function at all.
So why are people even writing these types of tests? Well, let me be a bit blasphemous here, and call out one of the reasons I have seen used to justify this setup: coverage metrics. Coverage metrics are a way to evaluate whether tests have been written that “cover” the whole of the program. The concept is designed so that you strive to exercise all of the conditional parts of your software during testing, so the goal is to have 100% of the source code “covered”.
Unfortunately, while the concept is a great idea, the execution is often dogmatic, with a straight ratio of expected coverage for every source file. The “incremental coverage” metric is a similar concept that suggests that you don’t want to ever reduce the coverage of tests. Again, a very useful metric to get an idea if the changes are unintentionally losing coverage, but not something that I would consider giving a strict order to.
This is not to mean that coverage metrics are not useful, or that it’s okay to not exercise parts of a program through the testing cycle — I just think that coverage metrics in the innermost layer are disingenuous and sometimes actively harmful, by introducing all-mocks and change-detector tests. I’ll get to where I think they are useful later.
Ideally, I would say that you don’t want this layer of tests to take more than a couple of minutes, with five being on the very high margin. Again, this falls back on the cost of asking changes — if going back to make a “trivial” change would require another round of tests consuming half an hour, there’s an increase chance that the would insist on making that change later, when they’ll be making some other change instead.
As I said earlier, there’s also matters of trade-offs. If the unit testing is such that it doesn’t require particular resources, and can run relatively quickly through some automated system, the cost to the author is reduced, so that a longer runtime is compensated by not having to remember to run the tests and report the results.
Looks Good To Me — Make sure it doesn’t break anything
There is a second layer of testing that fits on top of the first one, once the change is reviewed and approved, ready to be merged or landed. Since ideally your change does not have defects and you want to just make sure of it, you are going to be running this layer of testing once per change you want to apply.
In case of a number of related changes, it’s not uncommon to run this test once per “bundle” (stack, patchset, … terminology changes all the time), so that you only care that the whole stack works together — although I wouldn’t recommend it. Running one more layer of test on top of the changes make it easier to ensure they are independent enough that one of them can be reverted (rolled back, unlanded) safely (or at least a bit more safely).
This layer of tests is what is often called “integration” testing, although that term is still too ambiguous to me. At this layer, I would be caring to make sure that the module I’m changing still exposes an interface and a behaviour consistent with the expectation from the consumer modules, and still consumes data as provided by its upstream interfaces. Here I would avoid mocks unless strictly required, and rather prefer “fakes” — with the caveat that sometimes you want to use the same patching techniques as used with mocks, particularly if your interface is not well suited for dependency injection.
As long as these tests are made asynchronous and reliable, they can take much longer than the pre-review unit tests — I have experience environments in which the testing after approval and before landing take over half hour, and it’s not that frustrating… as long as they don’t fail for reasons outside of your control. This usually comes down to handling being able to have confidence in sequencing solutions and the results of the tests — nothing is more frustrating than waiting for two hours to land a change just to be told “Sorry, someone else landed another change in the meantime that affects the same tests, you need to restart your run.”
Since the tests take longer, this layer has more leeway in what it can exercise. I personally would strictly consider network dependencies off-limits: as I said above you want to have the confidence in the result, and you don’t want that your change failed to merge because someone was running an update on the network service you rely upon, dropping your session.
So instead, you look for fakes that can implement just enough of the interaction to provide you with signal while still being under your control. To make an example, consider an interface that takes some input, processes it and then serializes some data into a networked datastore: the first layer unit test would focus on making sure that the input processing is correct, and that the resulting structure contains the expected data given a certain input; this second layer of tests would instead ask to serialize the structure and write it to the datastore… except that instead of the real datastore dependency, you mock or inject a fake one.
Depending on the project and the environment, this may be easier said than done, of course. In big enterprises it isn’t unexpected for a team providing a networked service to also maintain a fake implementation of it. Or at least maintain an abstraction that can be used both with the real distributed implementation, and with a local, minimal version. In the case of a datastore, it would depends on how it’s implemented in the first place: if it’s a distributed filesystem, its interface might just be suitable to use both with the network path and with a local temporary path; if it’s a SQL database, it might have an alternative interface using SQLite.
For FLOSS projects this is… not always an easy option. And this gets even worse when dealing with hardware. For my glucometerutils project, I wouldn’t be able to use fake meters — they are devices that I’m accessing, after all, without the blessing of their original manufacturer. On the other hand, if one of them was interested in having good support for their device they could provide a fake, software implementation of it, that the tool can send commands to and explore the results of.
This layer can then verify that your code is not just working, but it’s working with the established interfaces of its upstreams. And here is where I think coverage metrics are more useful. You no longer need to mock all the error conditions upstream is going to give you for invalid input — you can provide that invalid input and make sure that the error handling is actually covered in your tests.
Because the world is made of trade offs, there’s more trade offs to be made here. While it’s possible to run this layer of tests for a longer time than the inner layer, it’s still often not a good idea to run every possible affected test, particularly when working in a giant monorepo, and on core libraries. In these situations an often used trade off has most changes going through a subset of tests – declared as part of the component being changed – with the optional execution of every affected test. It relies on manually curated test selection, as well as a comprehensive dependency tracking, but I can attest that it scales significantly better than running every possibly affected test all the time.
Did we all play well together?
One layer up, and this is what I call Integration Testing. In this layer, different components can (and should) be tested together. This usually means that instead of using fakes, you’re involving networked services, and… well, you may actually have flakes if you are not resilient to network issues.
Integration testing is not just about testing your application, but it’s also testing that the environment around it works along with it. This brings up an interesting set of problems when it comes to ownership. Who owns the testing? Well, in most FLOSS projects the answer is that the maintainers of a project own the testing of their project, and their project only. Most projects don’t really go out of their way to try to and figure out if the changes to their main branch cause issues to their consumers, although a few, at least when they are aware that the changes may break downstream consumers, might give it a good thought.
In bigger organizations, this is where things become political, particularly when monorepos are involved — that’s because it’s not unreasonable for downstream users to always run their integration tests against the latest available version of the upstream service, which is more likely to bump into changes and bugs of the upstream service than the system under actual test (at least after the first generation of bugs and inconsistencies is flattened out).
As you probably noticed by now, going up the layers also means going up in cost and time. Running an integration test with actual backends is no exception to this. You also introduce a flakiness trade-off — you could have an integration test that is always completely independent between runs, but to do so you may need to wait for a full bring-up of a test environment at each run; or you could accept some level of flakes, and just reuse a single test environment setup. Again, this is a matter of trade-offs.
The main trade-off to be aware of is the frequency of certain type of mistakes over others. The fastest tests (which in Python I’d say should be type checking rather than “actual testing”) should be covering mainly the easy-to-make mistakes (e.g. bytes vs str), while the first layer of testing should cover the interfaces that are the easiest to get wrong. Each layer of tests take more time and more resources than the one below, and so it should be run less often — you don’t want to run the full integration tests on drafts, but also you may not be able to afford running it on each submitted change — so maybe you batch changes to test, and reduce the scope of the failure within a few dozens.
But what it if it does fail, and you don’t know which one of the dozen broke it? Well, that’s something you need to get an answer for yourself — in my experience, what makes it easy at this point is not allowing further code changes to be landed until the culprit change is found, and only using revisions that did pass integration testing as valid “cutting points” for releases. And if your batch is small enough, it’s much faster to have a bisection search between the previous run and the current.
If It Builds, Ship It!
At this point, you may think that testing is done: the code is submitted, it passed integration testing, and you’re ready to build a release — which may again consists on widely different actions: tag the repository, build a tarball of sources, build an executable binary, build a Docker image, …
But whatever comes here, there’s a phase that I will refer to as qualifying a release (or cut, or tag, or whatever else). And in a similar fashion as to what I did in Gentoo, it’s not just a matter to make sure that it builds (although that’s part of it, and that by itself should be part of the integration tests), it also needs to be tested.
From my experience here, the biggest risk at this stage is to make sure that the “release mode” of an application works just as well as the “test mode”. This is particularly the case with C and other similar languages in which optimizations can lead to significantly different code being executed than in non-optimized code — this is, after all, how I had to re-work unpaper tests. But it might also be that the environments used to build the integration testing and the final releases are different, and because of that the results are different with that.
Again, this will take longer — although this time it’s likely that the balance of time spent would be on the build side rather than the execution time: optimizing a complex piece of software into a final released binary can be intensive. This is the reason why I would expect that test and release environments wouldn’t be quite the same, and the reason why you need a separate round of testing when you “cut” a release somehow.
Rollin’
That’s not the last round of “testing” that is involved in a full, end-to-end, testing view: when a release is cut, it needs to be deployed – rolled out, published, … – and that in general needs some verification. That’s because even though all of the tests might have passed perfectly fine, they never hit their actual place in a production environment.
This might sound biased towards distributed systems, such as cloud offerings and big organizations like my current and previous employers, but you have the same in a number of smaller environments too: you may have tested something in the staging environment as part of release testing, but are you absolutely certain that the databases running the production environment are not ever so slightly different? Maybe it’s a different user that typed in the schema creation queries, or maybe the hostname scheme between the two is such that there’s an unexpected character in the latter that crashes your application at startup.
This layer of testing is often referred to as healthchecks, but the term has some baggage so I wouldn’t stay too attached to it. In either case, while often these are not considered tests per-se, but rather part of monitoring, I still consider them part of the testing layers. That is also because, if a system is sufficiently complex and critical, you may implement them exactly as part of testing, by feeding it a number of expected requests and observe the results.
Final Thoughts
Testing is a complicated matter, and I’m not promising I gave you any absolute truth that will change your life or your professional point of view. But I hope this idea of “layering” testing, and understanding that different interactions can only be tested at different layers, will give you something to go by.
Hi,
Regarding intentionally introducing bugs, I was joking about that myself.
Last summer, we had a customer with 24-hour support and this responsibility would be switched between different employees week by week. If the employee on call handled an incident outside of working hours, the employee received a fixed reward to compensate for being woken up in the middle of the night. Of course, you can see the natural conflict of interest there—and I actually did unintentionally introduce a bug which resulted in me responding to various issues and receiving such compensation. It wasn’t intentional, but we joked that it was ;-).
This customer also experienced issues resulting from our queries triggering bad query plan generation in SQL Server. In our development environments with almost no data—or when we manually ran queries in their systems—things would always perform well because the query optimizer is actually pretty good. But in trying to cache its results to save resources on plan generation for repeated queries, sometimes a query which SQL Server could answer in seconds would take minutes, oftentimes exceeding a default 30 second timeout built into .net’s SqlCommand—and, even if it didn’t time out, this resulted in unacceptable performance. This is a sort of thing that is hard to test and I guess that makes it fall into that “health check testing” concept a bit…?
The concept of health check testing reminds me of how we operate a little bit. We deploy into a customer’s test environment and let them exercise the system there. But after a deploy to production, we definitely try to stay around a bit and make sure things stay up for a little bit and really pressure the customer to try to run at least one order through the system prior to calling it a day. If this doesn’t happen, the customer may be stuck with an inoperable system the next morning. Sometimes, unfortunately, parts of some changes only ever do get tested in this way too. So, with this way of applying terminology, I can ship stuff without testing it and then claim that the process of observing it after “shipping” is itself testing ;-).
Actually, I do like using tests as a way to develop. I do not like to manually run steps in our system to test if my code is working—I’d rather spend (way too too much, unfortunately) time writing something to automatically do that for me. Unfortunately, we have a big collection of tests which is too slow and unwieldy to actually run and keep working as a result. As I develop features, I manually select a few (which is something you mentioned in your post) which I expect to be most relevant to what I am doing and which run in a reasonable amount of time to try to exercise the bits of the system which I expect to be (unintentionally) breaking as I refactor.
Thanks for continuing to post! I enjoy reading them but I am quite good at mismanaging my time x.x.