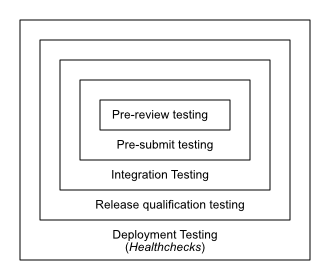
English Technical2021-03-23 Testing is Like Onions: They Have Layers, And They Make You Cry Flameeyes