It’s well possible that a number of people reading this post have already stumbled across a few of the “Falsehoods Programmers Believe…” documents. If not, there appears to be a collection of them, although I have honestly only read through the ones about names, addresses, and time. The short version of all of this, is that interfacing software with reality is complicated, and in many cases, programmers don’t know how complicated it is at all. And sometimes this turns into effectively institutional xenophobia.
I have already mused that tutorials and documentation are partially to blame, by spreading code memes and reality-hostile simplifications. But now I have some more evidence of this being the case, without me building an explicit strawman like I did last time, and that brings me to another interesting point, in regards to the raising importance of getting stuff right beforehand, as costs to correct these mistakes are raising.
You see, with lockdown giving us a lot of spare time, I spent some of it on artsy projects and electronics, while my wife spent it learning about programming, Python, and more recently databases. She found a set of tutorials on YouTube that explain the basis of what a database is, and how SQL works. And they were full of those falsehoods I just linked above.
The tutorials use what I guess is a fairly common example of using a database for employees, customers, and branches of a company. And it includes in the example the fields for first name and last name. Which frankly is a terrible mistake — with very few exception that include banks and airlines, there’s no need to distinguish between components of a name, and a simple full name field would work just as well, and don’t end up causing headaches to people from cultures that don’t split names the same way. The fact that I recently ranted about this on Twitter against VirusTotal is not totally coincidental.
It goes a bit beyond that though, by trying to explain ON DELETE triggers by attaching them to the deletion of an employee from the database. Now, I’m not a GDPR lawyer, but it’s my understanding that employee rosters are one of those things that you’re allowed to keep for essential business needs — and you most likely don’t want to ever delete employees, their commissions payment history, and tax records.
I do understand that a lot of tutorials need to be using simple examples, as setting up a proper HR-compatible database would probably take a lot more time, particularly with compartmentalizing information so that your random sales analyst don’t have access to the home phone numbers of their colleagues.
I have no experience with designing employee-related database schemas, so I don’t really want to dig myself into a hole I can’t come out of, by running with this example. I do have experience with designing database schemas for product inventory, though, so I will run with that example. I think it was a different tutorial that was talking about those, but I’ll admit I’m not sure, because I didn’t pay too much attention as I was getting annoyed at the quality.
So this other tutorial focused on products, orders and sales total — its schema was naïve and not the type of databases any real order history system would use — noticeably, it assumed that an order would just need to connect with the products, with the price attached to the product row. In truth, most databases like those would need to attach the price for which an item was sold to the order — because products change prices over time.
And at the same time, it’s fairly common to want to keep the history of price changes for an item, which include the ability to pre-approve time-limited discounts, so a table of products is fairly unlikely to have the price for each item as a column. Instead, I’ve commonly seen these database to have a prices table that references the items, and provides start and end dates for the price. This way, it’s possible to know at any time what is the “valid price” for an item. And as some of my former customers had to learn on their own, it’s also important to separate which VAT is used at which time.
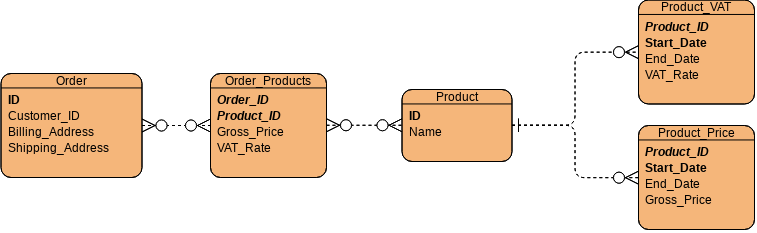
This is again fairly simplified. Most of the shopping systems you might encounter use what might appear redundant, particularly when you’re taught that SQL require normal form databases, but that’s just in theory — practice is different. Significantly so at times.
Among other things, if you have an online shop that caters to multiple countries within the European Union, then your table holding products’ VAT information might need to be extended to include the country for each one of them. Conversely, if you are limited to accounting for VAT in a single country you may be able to reduce this to VAT categories — but keep in mind that products can and do change VAT categories over time.
Some people might start wondering now why would you go through this much trouble for an online store, that only needs to know what the price is right now. That’s a good point, if you happen to have multiple hundreds’ megabytes of database to go through to query the current price of a product. In the example above you would probably need a query such as
SELECT Product.ID, Product.Name, Product_Price.Gross_Price, Product_VAT.VAT_Rate
FROM Product
LEFT JOIN Product_Price ON Product_Price.Product_ID = Product.ID
LEFT JOIN Product_VAT ON Product_VAT.Product_ID = Product.ID
WHERE
Product.ID = '{whatever}' AND
Product_Price.Start_Date <= TODAY() AND
Product_Price.End_Date > TODAY() AND
Product_VAT.Start_Date <= TODAY() AND
Product_VAT.End_Date > TODAY();Code language: HTML, XML (xml)It sounds like an expensive query, doesn’t it? And it seems silly to go and scan the price and VAT tables all the time throughout the same day. It also might be entirely incorrect, depending on its placement — I do not know the rules of billings, but it may very well be possible that an order be placed close to a VAT change boundary, in which case the customer could have to pay the gross price at the time of order, but the VAT at shipping time!
So what you do end up using in many places for online ordering is a different database. Which is not the canonical copy. Often the term used for this is ETL, which stands for Extract, Transform, Load. It basically means you can build new, read-only tables once a day, and select out of those in the web frontend. For instance the above schema could be ETL’d to include a new, disconnected WebProduct table:
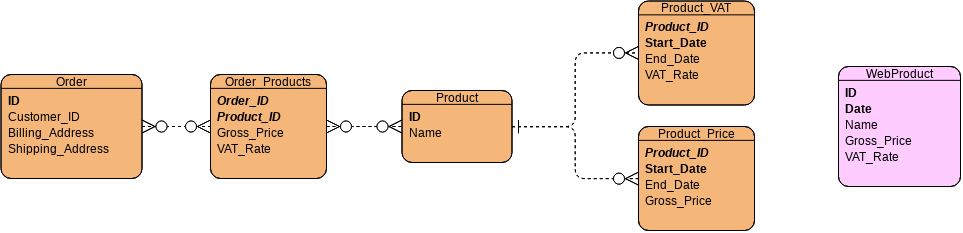
Now with this table, the query would be significantly shorter:
SELECT ID, Name, Gross_Price, VAT_Rate
FROM WebProduct
WHERE ID = '{whatever}' AND Date = TODAY();Code language: JavaScript (javascript)The question that comes up with seeing this schema is “Why on Earth do you have a Date column as part of the primary key, and why do you need to query for today’s date?” I’m not suggesting that the new table is generated to include every single day in existence, but it might be useful to let an ETL pipeline generate more than just one day’s worth of data — because you almost always want to generate today’s and tomorrow’s, that way you don’t need to take down your website for maintenance around midnight. But also, if you don’t have any expectation that prices will fluctuate on a daily basis, it would be more resource-friendly to run the pipeline every few days instead of daily. It’s a compromise of course, but that’s what system designing is there for.
Note that in all of this I have ignored the issue of stock. That’s a harder problem, and one that might not actually be suited to be solved with a simple database schema — you need to come to terms with compromises around availability and the fact that you need a single source of truth for how many items you’re allowed to sell… consistency is hard.
Closing my personal rant on database design, there’s another problem I want to point a spotlight to. When I started working on Autotools Mythbuster, I explicitly wanted to be able to update the content, quickly. I have had multiple revisions of the book on the Kindle Store and Kobo, but even those lagged behind the website a few times. Indeed, I think the only reason why they are not lagging behind right now is that most of the changes on the website in the past year or two have only been cosmetics, and not applying to ePub.
Even for a project like that, which uses the same source of truth for the content, there’s a heavy difference in the time cost of updating the website rather than the “book”. When talking about real books, that’s an even bigger cost — and that’s without going into the print books realm. Producing content is hard, which is why I realised many years ago that I wouldn’t have the ability to carve out enough time to make a good author.
Even adding diagrams to this blog post has a slightly higher cost than just me ranting “on paper”. And that’s why sometimes I could add more diagrams with my ideas, but I don’t, because the cost of producing it, and keeping it current would be too high. The Glucometers Protocols site as a few rough diagrams, but they are generated with blockdiag so that they can be edited quickly.
When it comes to online tutorial, though, there’s an even bigger problem: the possibly vast majority of them are, nowadays, on YouTube, as videos shot with a person in frame, to be more like a teacher in a classroom, that can explain things. If something in the video is only minimally incorrect, it’s unlikely that those videos would be re-shot — it would be an immense cost in time. Also, you can’t just update a YouTube video like you do a Kindle book — you lose comments, likes, view-counts, and those things matter for monetization, which is what most of those tutorials out there are made for. So unless the mistakes in a video-tutorial are Earth-shattering, it’s hard to expect the creators to go and fix them.
Which is why I think that it’s incredibly important to get the small things right — Stop using first and last name fields in databases, objects, forms, and whatever else you are teaching people to make! Think a bit harder as for how a product inventory database would look like! Be explicit in pointing out that you’re simplifying to an extreme, rather than providing a real-world-capable design of a database! And maybe, just maybe, start using examples that are ridiculous enough that they don’t risk being used by a junior developer in the real world.
And let me be clear on this: you can’t blame junior developers for making mistakes such as using a naïve database schema, if that’s all they are taught! I have been saying this at previous dayjob for a while: you can’t complain about the quality of code of newbies unless you have provided them with the right information in the documentation — which is why I spent more time than average on example code, and tutorials, to fix up trimmings and make it easier to copy-paste the example code into a working change that follows best practices. In the words of a colleague wiser than me: «Example code should be exemplar.» — update 2024-04-14: I now refer to it as Nathaniel’s Nudge.
So save yourself some trouble in the future, by making sure the people that you’re training get the best experience, and can build your own next tool to the best of specs.