If you’re here looking for information on the FreeStyle Libre 2, please see this other series of posts, and this issue on GitHub. Reverse engineering is proceeding slowly, and collaboration is key.
I have already reviewed the Abbott FreeStyle Libre continuous glucose monitor, and I have hinted that I already started reverse engineering the protocol it uses to communicate with the (Windows) software. I should also point out that for once the software does provide significant value, as they seem to have spent more effort in the data analysis than any other part of it.
Please note that this is just a first part for this device. Unlike the previous blog posts, I have not managed yet to get even partial information downloaded with my script as I write and post this. Indeed, if you, as you read this, have any suggestion of things I have not tried yet, please do let me know.
Since at this point it’s getting common, I’ve started up the sniffer, and sniffed starting from the first transaction. As it is to be expected, the amount of data in these transactions is significantly higher than that of the other glucometers. Even if you were taking seven blood samples a day for months with one of the other glucometers, it’s going to take a much longer time to get the same amount of readings as this sensor, which takes 96 readings a day by itself, plus the spot-checks and added notes and information to comment them.
The device itself presents itself as a standard HID device, which is a welcome change from the craziness of SCSI-based hidden message protocols. The messages within are of course not defined in any standard of course, so inspecting them become interesting.
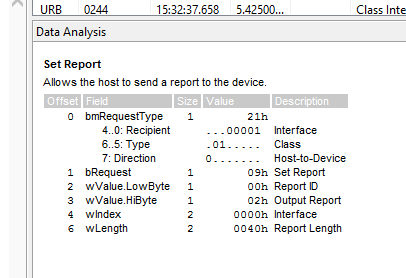
It took me a while to figure out what the data that the software was already decoding for me meant. At first I thought I would have to use magic constant and libusb to speak raw USB to the device — indeed, a quick glance around Xavier’s work showed me that there were plenty of similarities, and he’s including quite a few magical constants in that code. Luckily for me, after managing to query the device with python-libusb1, which was quite awkward as I also had to fix it to work, I realized that I was essentially reimplementing hidraw access.
After rewriting the code to use /dev/hidraw1 (which makes it significantly simpler), I also managed to understand that the device uses exactly the same initialization procedure as the FreeStyle InsuLinx that Xavier already implemented, and similar but not identical command handling (some of the commands match, and some even match the Optium, at least in format.)
Indeed the device seem to respond to two general classes of commands: text-commands and binary commands, the first device I reverse engineer with such a hybrid protocol. Text commands also have the same checksumming as both the Optium and Neo protocols.
The messages are always transferred in 64-bytes packets, even though the second byte of the message declares the actual significant length, which can be even zero. Neither the software nor the device zero out their buffers before writing the new command/response packets, so there is lots of noise in those packets.
I’ve decided that the custom message framing and its usage of HID is significant enough to warrant being documented by itself so I did that for now, although I have not managed to complete the reverse engineering of the protocol.
The remaining of the protocol kept baffling me. Some of the commands appear to include a checksum, and are ignored if they are not sent correctly. Others actually seem to append to an error buffer that you can somehow access (but probably more by mistake than design) and in at least one case I managed to “crash” the device, which asked me to turn it off and on again. I have thus decided to stop trying to send random messages to it for a while.
I have not been pouring time on this as much as I was considering doing before, what with falling for a bad flu, being oncall, and having visitors in town, so I have only been looking at traces from time to time, particularly recording all of them as I downloaded more data out of it. What still confuses me is that the commands sent from the software are not constant across different calls, but I couldn’t really make much heads or tails of it.
Then yesterday I caught a break — I really wanted to figure out at least if it was encoding or compressing the data, so I started looking for at least a sequence of numbers, by transcribing the device’s logbook into hexadecimal and looking in the traces for them.
This is not as easy as it might sound, because I have a British device — in UK, Ireland and Australia the measure of blood sugar is given in mmol/l rather than the much more common mg/dl. There is a stable conversion between the two units (you multiply the former by 18 to get the latter), but this conversion usually happens on display. All the devices I have used up to now have been storing and sending over the wire values in mg/dl and only converted when the data is shown, usually by providing some value within the protocol to specify that the device is set to use a given unit measure. Because of this conversion issue, and the fact that I only had access to the values mmol/l, I usually had two different options for each of the readings, as I wasn’t sure how the rounding happened.
The break happened when I was going through the software’s interface, trying to get the latest report data to at least match the reading timing difference, so that I could look for what might appear like a timestamp in the transcript. Instead, I found the “Export” function. The exported file is a comma-separated values file, which includes all readings, including those by the sensor, rather than just the spot-checks I could see from the device interface and in the export report. Not only that, but it includes a “reading ID”, which was interesting because it started from a value a bit over 32000, and is not always sequential. This was lucky.
I imported the CSV to Google Sheets, then added columns next to the ID and glucose readings. The latter were multiplied by 18 to get the value in mg/dl (yes the export feature still uses mmol/l, I think it might be some certification requirement), and then convert the whole lot to hexadecimal (hint: Google Sheets and LibreOffice have a DEC2HEX function that do that for you.) Now I had something interesting to search for: the IDs.
Now, I have to point out that the output I have from USBlyzer is a CSV file that includes the hexdump of the USB packets that are being exchanged. I already started writing a set of utilities (too rough to be published though) to convert those into a set of binary files (easier to bgrep or binwalk them) or hexdump-like transcripts (easier to recognize strings.) I wrote both a general “full USB transcript” script as well as a “Verio-specific USB transcript” while I was working on my OneTouch meter, so I wrote one for the Abbott protocol, too.
Because of the way that works, of course, it is not completely obvious if any value which is not a single byte is present, by looking at the text transcript, as it might be found on the message boundary. One would think they wouldn’t, since that means there are odd-sized records, but indeed that is the case for this device at least. Indeed it took me a few tries of IDs found in the CSV file to find one in the USB transcript.
And even after finding one the question was to figure out the record format. What I have done in the past when doing binary format reverse engineering was to print on a piece of paper a dump of the binary I’m looking at, and start doodling on it trying to mark similar parts of the message. I don’t have a printer in Dublin, so I decided to do a paperless version of the same, by taking a screenshot of a fragment of transcript, and loading it into a drawing app on my tablet. It’s not quite as easy, but it does making sharing results easier and thanks to layers it’s even easier to try and fail.
I made a mistake with the screenshot by not keeping the command this was a reply to in the picture — this will become more relevant later. Because of the size limit in the HID-based framing protocol Abbott uses, many commands reply with more than one message – although I have not understood yet how it signals a continuation – so in this case the three messages (separated by a white line) are in response to a single command (which by the way is neither the first or the last in a long series.)
The first thing I wanted to identify in the response was all the reading IDs, the one I searched for is marked in black in the screenshot, the others are marked in the same green tone. As you can see they are not (all) sequential; the values are written down as little-endian by the way. The next step was to figure out the reading values, which are marked in pink in the image. While the image itself has no value that is higher than 255, thus using more than bytes to represent them, not only it “looked fair” to assume little endian. It was also easy to confirm as (as noted in my review) I did have a flu while wearing the sensor, so by filtering for readings over 14 mmol/L I was able to find an example of a 16-bit reading.
The next thing I noted was the “constant” 0C 80 which might include some flags for the reading, I have not decoded it yet, but it’s an easy way to find most of the other IDs anyway. Following from that, I needed to find an important value, as it could allow decoding many other record types just by being present: the timestamp of the reading. The good thing with timestamps is that they tend to stay similar for a relative long time: the two highest bytes are the same for most of a day, and the highest of those is usually the same for a long while. Unfortunately looking for the hex representation of the Unix timestamp at the time yield nothing, but that was not so surprising, given how I found usage of a “newer” epoch in the Verio device I looked at earlier.
Now, since I have the exported data I know not only the reading ID but also the timestamp it reports it at, which does not include seconds. I also know that since the readings are (usually) taken at 15 minutes intervals, if they are using seconds since a given epoch the numbers should be incrementing by 900 between readings. Knowing this and doing some mental pattern matching it became easy to see where the timestamps have been hiding, they are marked in blue in the image above. I’ll get back to the epoch.
At this point, I still have not figured out where the record starts and ends — from the image it might appear that it starts with the record ID, but remember I took this piece of transcript mid-stream. What I can tell is that the length of the record is not only not a multiple of eight (the bytes in hexdump are grouped by eight) but it is odd, which, by itself, is fairly odd (pun intended.) This can be told by noticing how the colouring crosses the mid-row spacing, for 0c 80, for reading values and timestamps alike.
Even more interesting, not only the records can cross the message boundaries (see record 0x8fe0 for which the 0x004b value is the next message over), but even do the fields. Indeed you can see on the third message the timestamp ends abruptly at the end of the message. This wouldn’t be much of an issue if it wasn’t that it provides us with one more piece of information to decode the stream.
As I said earlier, timestamps change progressively, and in particular reading records shouldn’t usually be more than 900 seconds apart, which means only the lower two bytes change that often. Since the device uses little-endian to encode the numbers, the higher bytes are at the end of the encoded sequence, which means 4B B5 DE needs to terminate with 05, just like CC B8 DE 05 before it. But the next time we encounter 05 is in position nine of the following message, what gives?
The first two bytes of the message, if you checked the protocol description linked earlier, describe the message type (0B) and the number of significant bytes following (out of the usb packet), in this case 3E means the whole rest of the packet is significant. Following that there are six bytes (highlighted turquoise in the image), and here is where things get to be a bit more confusing.
You can actually see how discarding those six bytes from each message now gives us a stream of records that are at least fixed length (except the last one that is truncated, which means the commands are requesting continuous sequences, rather than blocks of records.) Those six bytes now become interesting, together with the inbound command.
The command that was sent just before receiving this response was 0D 04 A5 13 00 00. Once again the first two bytes are only partially relevant (message type 0D, followed by four significant bytes.) But A5 13 is interesting, since the first message of the reply starts with 13 A6, and the next three message increment the second byte each. Indeed, the software follows these with 0D 04 A9 13 00 00, which matches the 13 A9 at the start of the last response message.
What the other four bytes mean is still quite the mystery. My assumption right now is that they are some form of checksum. The reason is to be found in a different set of messages:
>>>> 00000000: 0D 04 5F 13 00 00 .._...
<<<< 00000000: 0B 3E 10 5F 34 EC 5A 6D 00 00 00 00 00 00 00 00 .>._4.Zm........
<<<< 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000020: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000030: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000000: 0B 3E 10 60 34 EC 5A 6D 00 00 00 00 00 00 00 00 .>.`4.Zm........
<<<< 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000020: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000030: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000000: 0B 3E 10 61 34 EC 5A 6D 00 00 00 00 00 00 00 00 .>.a4.Zm........
<<<< 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000020: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000030: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000000: 0B 3E 10 62 34 EC 5A 6D 00 00 00 00 00 00 00 00 .>.b4.Zm........
<<<< 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000020: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000030: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000000: 0B 3E 10 63 E8 B6 84 09 00 00 00 00 00 00 00 00 .>.c............
<<<< 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
<<<< 00000020: 00 00 00 00 9A 39 65 70 99 51 09 30 4D 30 30 30 .....9ep.Q.0M000
<<<< 00000030: 30 37 52 4B 35 34 00 00 01 00 02 A0 9F DE 05 FC 07RK54..........
Code language: CSS (css)In this set of replies, there are two significant differences compared to the ones with record earlier. The first is that while the command lists 5F 13 the replies start with 10 5F, so that not only 13 becomes 10, but 5F is not incremented until the next message, making it unlikely for the two bytes to form a single 16-bit word. The second is that there are at least four messages with identical payload (fifty-six bytes of value zero). And despite the fourth byte of the message changing progressively, the following four bytes are staying the same. This makes me think it’s a checksum we’re talking about, although I can’t for the life of me figure out which at first sight. It’s not CRC32, CRC32c nor Adler32.
By the way, the data in the last message relates to the list of sensors the devices has seen — 9ep.Q.0M00007RK54 is the serial number, and A0 9F DE 05 is the timestamp of it initializing.
Going back to the epoch, which is essentially the last thing I can talk about for now. The numbers above clearly shower in a different range than the UNIX timestamp, which would start with 56 rather than 05. So I used the same method I used for the Verio, and used a fixed, known point in time, got the timestamp from the device and compared with its UNIX timestamp. The answer was 1455392700 — which is 2012-12-31T00:17:00+00:00. It would make perfect sense, if it wasn’t 23 hours and 43 minutes away from a new year…
I guess that is all for now, I’m still trying to figure out how the data is passed around. I’m afraid that what I’m seeing from the software looks like it’s sending whole “preferences” structures that change things at once, which makes it significantly more complicated to understand. It’s also not so easy to tell how the device and software decide the measure unit as I don’t have access to logs of a mg/dl device.
Dear Diego,I am having a project in mind that I’d like to give it a try. It turns out that I practice sport often to keep my diabetes type 1 under control. It is not very handy when participating in a race that you have to stop or risk not to do so while testing blood glucose on a bike ride. My idea consist in implementing a hw based reader (NFC) that sends the info with (BLE) to a garmin device (monkey C language). However, since the data read out from the Libre is not standardized anywhere, I was wondering if you actually ended up finding out the coding of the data from the Libre.Thanks a lot in advance!Good blog by the way! keep it up!
I have not even tried reversing the NFC protocol — somebody did but I have no intention to follow through myself. The problem is that the calibration happens on the reader device rather than the sensor, so even if you can get the data out, it would not be reliable.For this kind of usage, a continuous 2.4GHz-radio glucometer that already sports BLE output might be a better fit.
HiI finally have a device on my own and I was digging into the protocol a little.I found out that with the commands from insulinx (https://github.com/xclaesse… you actually get quite far.With cmd 0x21 and msg $dbrnum? you get back the number of records you have (found this one in the trace).With cmd 0x60 and msg $result? you get back the results in a comma separated list. The only problem here is, that you only get the results you measured yourself (==> blood glucose and the results when you read out through NFC).Now if there is just a command which returns the rest as well and we are happy. But this is already a step.
cmd: 0x60msg = “$history?” returns the sensor readings.
Oh wow this is really nice information! I’m currently unable to test or work on this myself as I’m on a work trip, would you mind sending me a pull request for https://github.com/Flameeyes/glucometer-protocols with the information you found?Thank you very much!
Hi good night dear.I am from Brazil and want help this project. I get a sensor and i am testing read sensor. Can you tell me how interpret raw data. I identificated some lines… but have much data that I dont know what is.Can you help me to make this ? I want implement a bluetooth reader to this sensor. To dont need put smartphone in the arm to read sensor at night, and to generate alarms.Thank you.
Hi, good night.I am from Brazil and want help this project. I get a sensor and i am testing read sensor. Can you tell me how interpret raw data.I identificated some lines… but have much data that I dont know what is.Can you help me to make this ?I want implement a bluetooth reader to this sensor.To dont need put smartphone in the arm to read sensor at night, and to generate alarms.I found some values (freom freestyle)a2 85 0d 59 9e 085a2 is a glucose meter. 8 I dont know what is this bite, but 5a2 = 1442 = 144,2 mg/dl0d ?59 ?9e ?0 ?Do you know?Thank you.
That is fantastic. For my project http://www.glucosurfer.org I would like to develop a litte helper program to upload the data directly from the Libre to the user account. Does it make sense to start this work based on your current github project?
I have not pushed the mostly-working driver to glucometerutils yet, I plan on doing it this week after I manage to remove a couple of known bugs. If you do not play to reuse the code, but I expanded on Pascal’s contribution and you can use the protocol documented at https://protocols.glucometers.tech/abbott/freestyle-libre to get the data out.
Of couse I will wait for your driver. Big thanks for sharing!
I’ve now pushed the driver to GitHub, sorry for the delay.
Good work needs time! Thanks for making this world a better place!
Hi Diego, I’m curious if you ever figured out how to flash the unit entirely. The readers are much cheaper in some countries vs others and might be a way to lower the cost for patients, for instance in the US. Thanks!
I’d be super interested in that too!