I’m sorry it took so long but I had more stuff to write about in the mean time, and I’m really posting stuff as it comes with some pretty randomly ordered things.
In the post about the Portage Tree size I blandly and incompletely separate the overhead due to the filesystem block allocation from the rest of size of the components themselves. Since the whole data was gathered a night I was bored and trying to fixing up my kernel to have both Radeon’s KMS and the Atheros drivers working, it really didn’t strike as a complete work, and indeed it was just to give some sense of proportion on what is actually using up the space (and as you might have noticed, almost all people involved do find the size, and amount, of ChangeLogs a problem). Robin then asked for some more interesting statistics to look at, in particular the trend of the overhead depending on the size of the filesystem blocks.
This post, which comes after quite some angst is going to illustrate the results, although they do tend to be quite easy to see with the involved graphs. I hope this time the graphs do work for everybody out of the box; last time I used Google Docs to produce the output and linked it directly, this saved a lot of traffic on my side, but didn’t work for everybody. This time I’m going to use my blog’s server to publish all the results, hoping it won’t create any stir on it…
First of all, the data; I’m going to publish all the data I collected here, so that you can make use of it in any way you’d like; please note that it might not be perfect, knowledge about filesystems isn’t my favourite subject, so while it should be pretty consistent, there might be side-effects I didn’t consider; for instance, I’m not sure on whether directories have always the same size, and whether that size is the same for any filesystem out there; I assume both of these to be truths, so if I did any mistake you might have to adapt a bit the data.
I also hasn’t gone considering the amount of inodes used for each different configuration, and this is because I really don’t know for certainty how that behaves, and how to find how much space is used by the filesystem structures that handle inodes’ and files’ data. If somebody with better knowledge of that can get me some data, I might be able to improve the results. I’m afraid this is actually pretty critical to have a proper comparison of efficiency between differently-sized blocks because, well, the smaller the block the more blocks you need, and if you need more blocks, you end up with more data associated to that. So if you know more about filesystems than me and want to suggest how to improve this, I’ll be grateful.
I’m attaching the original spreadsheet as well as the tweaked charts (and the PDF of them for those not having OpenOffice at hand).
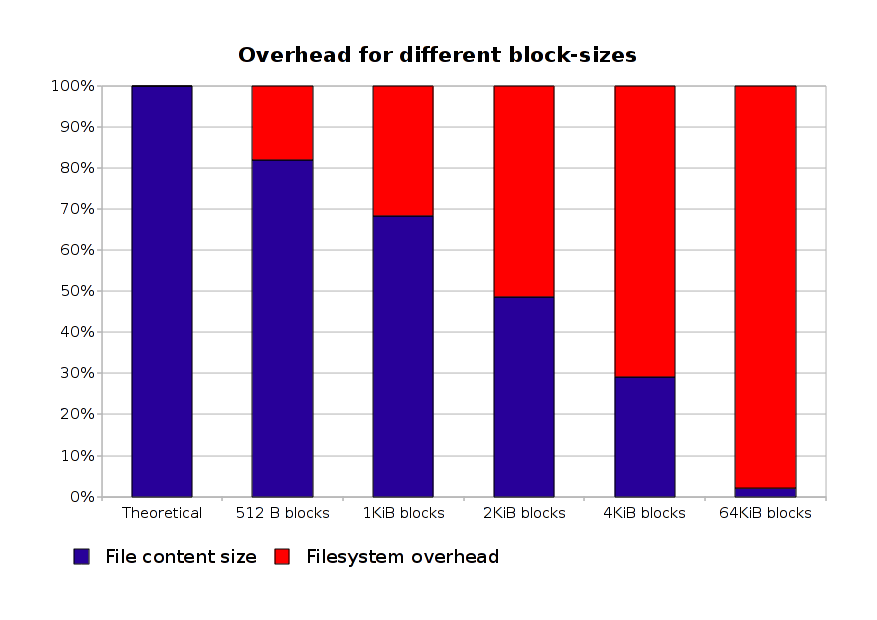
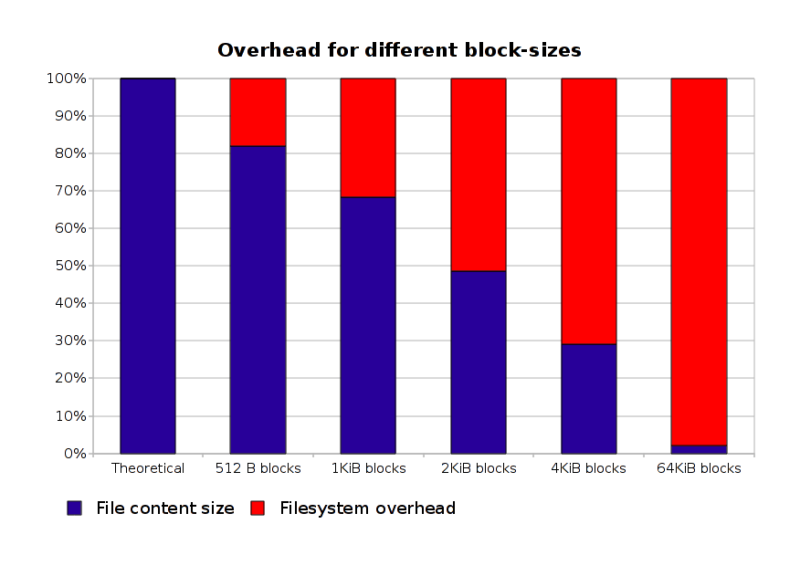
This first graph should give an idea about the storage efficiency of the Gentoo tree changes depending on the size block size: on the far left you got the theoretical point: 100% efficiency, where only the actual files that are in the tree are stored; on the far right an extreme case, a filesystem with 64KiB blocks… for those who wonder, the only way I found to actually have such a filesystem working on Linux is using HFS+ (which is actually interesting to know, I should probably put in such a filesystem the video files I have…); while XFS supports that in the specs, the Linux implementation doesn’t: it only supports blocks of the same size of a page, or smaller (so less than or equal to 4KiB) — I’m not sure why that’s the case, it seems kinda silly since at least HFS+ seems to work fine with bigger sizes.
With the “default” size of 4KiB (page size) the efficiency of the tree seems to be definitely reduced: it goes down to 30%, which is really not good. This really should suggest everybody who care about storage efficiency to move to 1KiB blocks for the Portage tree (and most likely, not just that).
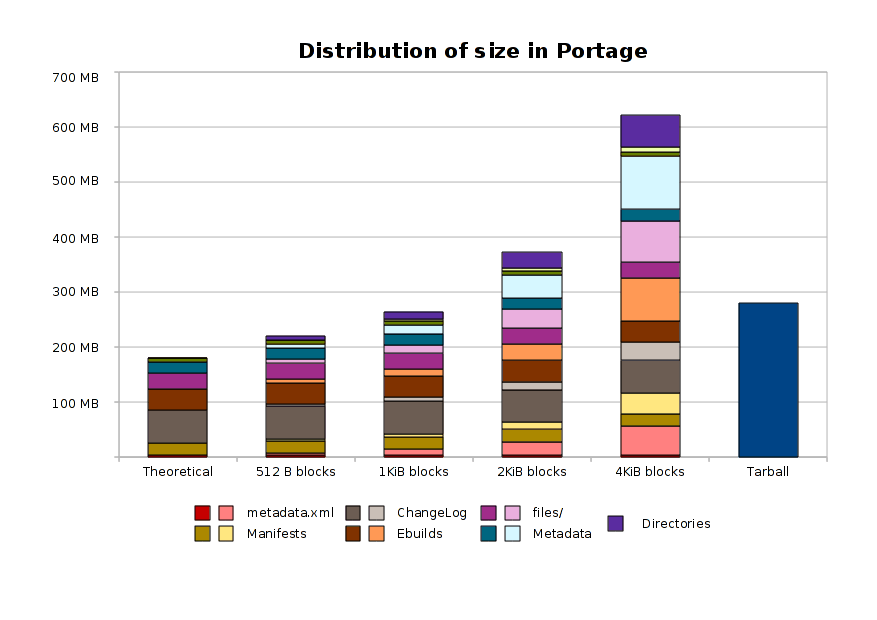
This instead should show you how the data inside the tree is distributed; note that I dropped the 64KiB-blocks case, this because the graph would have been unreadable: on such a filesystem, the grand total amounts of just a bit shy of 9GB. This is also why I didn’t go one step further and simulated all the various filesystems to compare the actual used/free space in them, and in the number of inodes.
*This is actually interesting, the fact that I wanted to comment on the chart, not leaving them to speak for themselves, let me find out that I did a huge mistake and was charting the complete size and the overhead instead of the theoretical size and the overhead in this chart. But it also says that it’s easier to note these things in graphical form rather than just looking at the numbers.*
So how do we interpret this data? Well, first of all, as I said, on a 4KiB-sized filesystem, Portage is pretty inefficient: there are too many small files: here the problem is not with ChangeLog (who still has a non-trivial overhead), but rather with the metadata.xml files (most of them are quite small), the ebuilds themselves, and the support files (patches, config files, and so on). The highest offender of overhead in such a configuration is, though, the generated portage metadata: the files are very small, and I don’t think any of them is using more than one block. We also have a huge amount of directories.
Now, the obvious solution to this kind of problems, is, quite reasonably actually, using smaller block sizes. From the reliability chart you can see already that without going for the very-efficient 512 bytes blocks size (which might starve at inode numbers), 1 KiB blocks size yields a 70% efficiency, which is not bad, after all, for a compromise. On the other hand, there is one problem with accepting that as the main approach: the default for almost all filesystems is 4KiB blocks (and actually, I think that for modern filesystems that’s also quite a bad choice, since most of the files that a normal desktop user would be handling nowadays are much bigger, which means that maybe even 128KiB blocks would prove much efficient), so if there is anything we can do to reduce the overhead for that case, without hindering the performance on 512 bytes-sized blocks, I think we should look into it.
As other have said, “throwing more disks at it” is not always the proper solution (mostly because while you can easily find how to add more disk space, it’s hard to get reliable disk space. I just added two external WD disks to have a two-level backup for my data…
So comments, ideas about what to try, ideas about how to make the data gathering more accurate and so on are definitely welcome! And so are links to this post on sites like Reddit which seems to have happened in the past few days, judging from the traffic on my webserver.
When converting a laptop from the 90ies (4 GB disk) into a remote controlled mp3 player I had similar issues. With modern disks the ionger time for an emerge resulting from cluster slag (= reduced throughput) should be more important than disk space.On first sight reiserfs3 seemed a viable choice. The tail merging option does away with “cluster slack”, where two file tails could share the same block. But reiserfs3 drastically slows down with frequent updates, see http://reiser4.wiki.kernel…. (Why is the execution time for a find . -type f | xargs cat {} ; command much longer when using ReiserFS than for the same command when using ext2?)nilfs should be worth a try. Fuse-zip is at version 0.2.7 since December 2008 and among other issues needs as much RAM as disk space. I wish ext4 had byte resolution in extents, resulting in a feature similar to tail merging.Compression would also help, but implementing random (write) access is difficult. I experimented with jffs2 and squashfs, but it was too cumbersome.The rsyncable architecture of portage is quite different from RPM, which uses a database. The sqlite approach to portage (http://www.gentoo-wiki.info… does something similar.portage-latest.tar.bz2 is just 35 MB, 43 MB with installed packages etc for my typical desktop. Portage version 3 could exploit the fact portage data is read-only for the (average) user. Employing some python modules, read only access should not be difficult. Rsync as the sole writer is structure-agnostic and could be applied in delta-mode, greatly reducing data transfer at the expense of server CPU. Maybe adding one compressed file per installed package is viable./var/db/pkg has a similar slack space issue.
You’re caring about portage overhead, but I’d go a step further…When Gentoo was created it was common that a PC wasn’t always connected to the internet, so a local copy of the central database was a very good thing. Today a PC without internet is a corner case, so do we really need a local copy of portage on every PC? Wouldn’t it be better if local portage was just an option for somebody who has no full time internet access or maybe wants to have a “frozen” portage? What I would like is a way to query and obtain ebuilds (and associated files) on demand from Gentoo servers, instead of rsyncing the full tree all the times. Is it something you ever considered?
After Johannes’ comment, it is perhaps time to announce the squashfs+aufs/unionfs initscript again:http://forums.gentoo.org/vi…It is useful not only for the portage tree, but also for /var/db/pkg, /usr/src/linux, /usr/share/{games,texmf-dist,doc}
Currently I’m using LVM to create a Portage partition using 1K blocks. Prior to that, I used a disk image, again with 1K blocks. The Portage tree takes up about 260 MB right now.
I don’t think that moving to an entirely over-the-network package manager is a smart choice, Internet connection or not; you have no idea how many times I found myself working without Internet access for a silly mistake of mine and still having to merge stuff around.Also, there is another problem with such an approach: when installing you still got to fetch recursively all the needed eclasses and then dependencies; since you cannot know whether they have been changed or not it might take quite some time.I don’t rule out that looking for a way to handle Portage for a few people at least, but there *has* at least to be a caching mechanism using reproducible etags (like checksums) that does not re-fetch everything over and over and over. And it would still not be nice ont he webservers, I’m afraid.
I’m for the “mostly-online” approach, too.What about only storing the ebuilds/metadata one actually uses on the pc? Let’s say, we start out with a very small set only containing @system and having a small “db” (may be a plaintext-file) containing what’s available(maybe only categories/names, not versions).Then, if the user installs some application, fetch the according ebuilds and store them locally, so in the future, only these things get synced? This way, basically build a `rsync –include`-list.Adding to that, create an “unsupported/unofficial”-subtree, to get rid of the IMHO very annoying overlay situation.Personally, I don’t want what I don’t need, using FEATURES=”nodoc noinfo noman” and getting it manually when needed.I don’t quite see, where this could be (very) bad for the servers, i.e. if I only query for a few packages I don’t see how this is more work than a complete sync of the tree.IMHO portage has grown to fast and maybe a hard cut is needed to make it ready for the future.
This is all very interesting work.Following your previous post, I’ve been looking into this myself, but from the compression perspective. Many of the comments on your previous post mentioned compression — I hope to come up with some statistical analysis to back up that suggestion soon (results so far are promising).I wrote “a script”:http://peripetylabs.blogspo… to gather size data of the local tree. It should help in speeding up experimentation. (Any feedback is welcome!)With regards to charts, I highly recommend Google’s “Chart API”:http://code.google.com/apis…. It’s especially useful for blogs (generated on-the-fly; hosted by Google).Keep up the good work!
“it is perhaps time to announce the squashfs+aufs/unionfs initscript again: (…)It is useful not only for the portage tree, but also for /var/db/pkg, /usr/src/linux, /usr/share/{games,texmf-dist,doc}”as much as i like it for /usr/portage, i deifnitely would not recommend it for /var/db/pkg. changes are uncommited to hard disk until you cleanly shutdown your pc, or force the script to rebuild squashfs image…. unless this script uses squashfs + some hard drive dir, and not squashfs + tmpfs, like mine.other than that it’s all pretty sweet. portage tree takes ~45mb on disk nowadays with this method.
I agree with flameeyes, you definately need portage offline available. Also think of –fetchonly, I use it freqently if I am at work to have a fast internet connection.squashfs would eat a lot of ram and system performance. I mean what is cheap newadays? The cheapest thing in my laptop is the harddrive (it has about 80GB), but only 1GB RAM and a 1.6GHz CPU. So I would advise to probably rewrite the documentation and suggest people to put /usr/portage on a small reiserfs (any other FS optimized for small files) partition or logical volume. This leaves a lot of flexibility to the user instead of forcing him to buy new hardware and install the 10th DB-system …I was wondering anyway why there are so many DB-Systems installed and as dependency to the system. For a normal Gnome install you need already db, sqlite, evolution and some more I cannot remember.Cheers,disi
i agree with Diego about offline-portage as I generally prefer to work always without internet to reduce distractions at minimum, so I need to compile stuff without an internet connection and this is a common scenario from the Gentoo users.A good solution to the problem can be to store all the portage tree in a pseudo-filesystem within a single file stored on a default 4KiB filesystem (single-file virtual filesystem like http://fossil.wanderinghors… ?), so the waste of space can be reduced at minimum and IO reads can take all the speed benefit of a 4KiB filesystem.
Here are a few recipes from my personal experience.1) I reduce disk space used by portage using an XFS FS with 512 or 1024 block size (can’t remember right now). What it gives?Filesystem Size Used Avail Use% Mounted on/dev/mapper/ravlyk_vol_group-usrportage 1014M 250M 765M 25% /usr/portagePortage tree takes only 250 MB actual space. The side effect is much faster processing of the tree on any extensive portage operation. I didn’t do the benchmarks, sorry, but is REALLY noticable2) I don’t use emerge –sync . I am using emerge-delta-webrsync from my early small-speed/expensive MB internet connection times. What I get? My portage tree is updated regularly as cron job and it only takes 100-200 Kbytes downloading per day, sometimes even less. Download size decreased significantly, duration as well, server load – of course!The only side effect is more time needed to decompress and “merge” the delta, but I’m not sure what will take more time on todays processors – full sync or delta decompressing and merging.As for the equilibrium suggestion I was thinking about the same thing when reading your series of portage tree size research. It could be just fine solution. Ready made image can be downloaded ungzipped and ready to use. Portage can mount it on demand if needed.There are some other thoughts running in my head, but ready to get written about them yet 🙂
“squashfs would eat a lot of ram and system performance. “i’ve been keeping /usr/portage on squashfs for about 2 years now, and i can say it’s mostly a false claim.squashfs handles itself pretty well on various livecds, and i don’t think it has bad performance.dependency calculation and all operations that involve accessing a lot of files inside /usr/portage (eix cache generation) have become much faster; i guess that’s because whole sqfs image gets cached into ram on my pc (probably), and aufs keeps modifications are kept in /dev/shm (that can be easily changed in the script, but i prefer it this way).the main problem is the event of power outage, or accidental reset – you lose changes from the last time you generated your squashfs image. you could opt to regenerate the image straight after syncing, just in case.the memory issue is true for low memory systems. in that case, switching from squashfs+tmpfs to squashfs+directory/temporary partition would be recommended.
IMO this problem is really a composition of more underlying problems and not incorrect filesystem settings.1. -one file: one ebuild scheme is quite inefficient, especially since 99% of the time ebuilds for different versions differ just in the eubild name.2. why should every user have whole tree on his machine ?Portage tree as it is has many other problems. Other day I was for example searching for useable CD/DVD recording SW, but couldn’t make my way throught the tree. Listing /usr/portage/category_name sucks, as well as emerge -s/earching.None of those problems can IMHO be really solved by FS tweaks and they demand more fundamental solution, which is probably theme for PortageV2/Gentoo-TNG debate…
“why should every user have whole tree on his machine ?” well, that is the fundamental problem of gentoo. everything is tucked into one tree (sunrise overlay is a decent example breaking this rule).i don’t think there is a fast way out of this.
Nice piece of work.If the problem is (a) lots of small files and (b) lots of text in the change log, as people commented on your first blog on this, why not zip up the data – say one zip file per atom?Possibly best would be to modify portage to handle both zipped and unzipped atom directories, so that developers can directly edit the files before zipping as part of release.I guess the downside would be a performance hit on such useful functions as emerge –search and similar activities in porthole, kuroo, etc. etc.
Another idea would be to inline very short support files in the ebuild. In some cases this would get rid of the whole files/ directory.I had filed http://bugs.gentoo.org/263565 some time ago for adding “-” for standard input to the newins function.
How about gzipping Changelogs and tarring files directory? Both changelogs and files are not used so frequently, so there will be no performance hit, but decrease of storage needed
> would not recommend it for /var/db/pkg. changes are uncommited to hard disk […] unless this script uses squashfs + some hard drive dir, and not squashfs + tmpfs, like mine.This is not the place to discuss this in detail; just let me note that the mentioned initscript supports both, but the recommended way is to use a permanent directory for DIR_CHANGE. So neither memory nor the mentioned safety problems occur.
i don’t think the quoted reiserfs-drawback is applicable here? rsync doesn’t write the data out in a given order, does it?
Awesome information indeed! I REALLY hate the “harddrives are cheap” argument (really, excuse). Even excluding changelogs all-together, portage is over 450mb on my jfs partition.Creating a separate partition just for my package manager seems kind of crazy too 🙂
[Joining late…]For me, having the “distfiles” under the actual “tree” was a bad idea which can be easily solved by using the DISTDIR variable in make.conf.After that, I create a (large) sparse file inside which I create a reiser4 fs (with compression enabled) and I mount it under /usr/portage.Here are some stats from a fresh tree running “emerge –sync” on an empty /usr/portage.> du -hcs *593M portage (256M if you use –apparent-size)268M portage-tree.tar 35M portage-tree.tar.bz2 47M portage-tree.tar.gz168M portage_reiser4.create=ccreg40The speed is great too! What to try it?# 1-create the sparse file (self-growing, up to 1Gb)dd if=/dev/zero of=/tmp/portage_reiser4 bs=1k count=1 seek=1024M# 2-create the reiser4 fsmkfs.reiser4 -o create=ccreg40 -f /tmp/portage_reiser4# 3- mount itmount -t reiser4 -o loop /tmp/portage_reiser4 /usr/portage# 4- have fun…Now what’s sad is that R4 isn’t in the official kernel. I’ve tried with btrfs (which also have compression) but the result isn’t great, something around 460M IIRC) I which we would have a compression mode on ext4…
@JPR, your `dd` command will create a 1TB sparse file. You only want seek to be 1M for a 1GB sparse file.dd if=/dev/zero of=/tmp/portage_reiser4 bs=1k count=1 seek=1M