I’m not referring to the usual programming mistake but to the endless problem of having build systems designed to run recursively, so that you have a single Makefile (or equivalent) rule file in each directory, and a top-level one to bridge them in.
Both within my “duties” in Gentoo and outside, I came to work heavily on fixing, managing, or at least (ab)using build systems. And since, when possible, I like my box to perform to its maximum potential, I’ve been a heavy maintainer that parallel make is the future to the point that I fixed a number of build systems myself, so that they built fine with parallel make.
But building fine is solving just half the problem; unfortunately a number of build systems are designed to work recursively, as I said above, and the result is that you only get a suboptimal parallel build out of them. How suboptimal? Well, I finally have a diagram to give an idea:
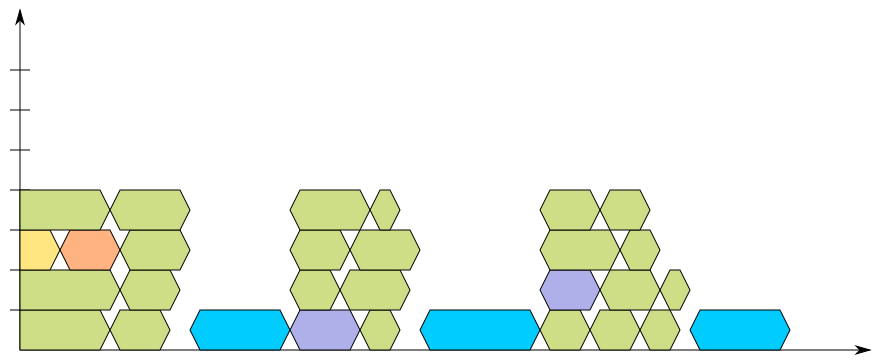
In this diagram – which is designed after the UML 2.0 new-style timing diagram, which in turn is unfortunately not supported by my tool of choice, I had drew them with Inkscape – you can see the flow of a recursive build using four jobs. Each of the “blocks” is a build job; for an easy understanding, think of the green ones as compiler calls (gcc), the purple ones as some code generator (such as ragel), while the yellow/orange pair is designed to be considered unrelated to the final output, such as a public header generator, or a documentation generator (this distinction is important, as another diagram later would shatter dependencies); finally the blue blocks are the link editor (ld).
Hopefully, the diagram is clear enough that the horizontal axis represents the time spent for the build, and thus the white spots over the linker calls should be easily understood as a sign that something is not performing to its full potential. If it isn’t as clear, then I should rethink the usefulness of the new-style timing diagram. The situation gets worse if you increase the job count to seven:
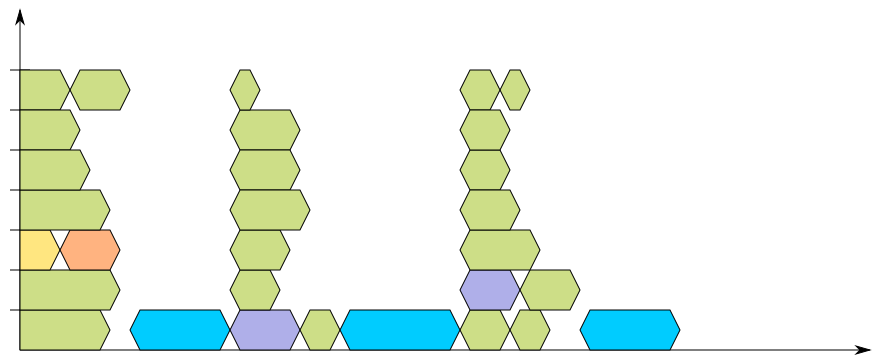
The problem here is that each recursion ends with a link editor call, which as we all know by now, is the slowest part of the process (even when using gold). This is the most common situation, when a package provides one or more shared libraries that are built and installed in the system, and one utility that makes use of those. But there is a positive fact to note here: when the recursively-built libraries are not installed, libtool is usually smart enough not to link them up with the link editor, but only create an archive file. Unfortunately this doesn’t work too well with build systems like evolution’s, that force the -module option. Sigh!
So why would you want to use non-recursive build systems? A non-recursive build system allows the build process to take care of all the independent units at once and leaving the dependent ones to finish, such as it is shown in the following two diagrams, where the build is instead modelled to be non-recursive:
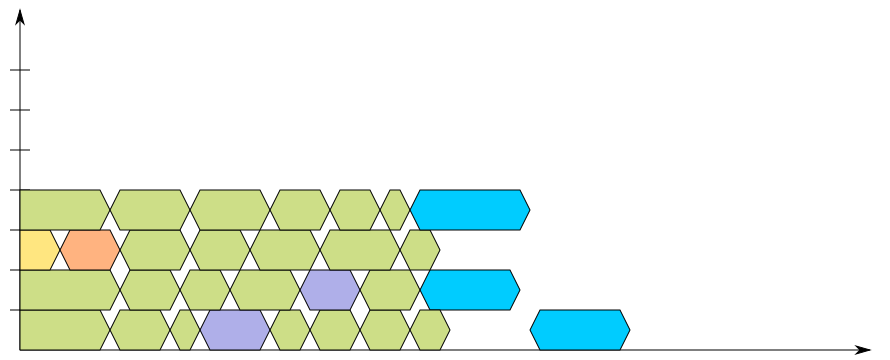
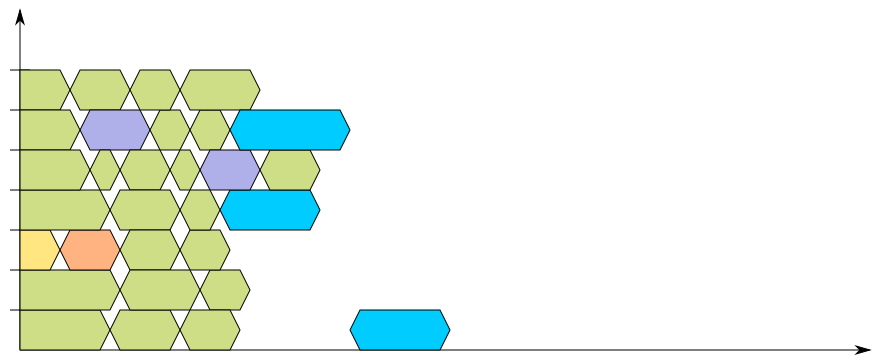
While the timing is not derived out of an actual build, by experience they should fit nicely with most of the builds you’ll found out there. It is probably interesting to note that if you have one final binary, you will still wait for all the other linking targets to be completed, which means you will lose most efficiency at the end of your build, but this is also the moment when most build systems build their documentation (to optimize this, automake makes it very explicit that executable targets are built before non-executable ones).
So why are recursive build systems still widely used? Well, there are a number of reasons unfortunately; some of them relate to style, others to complexity, and other again simply to upstream not being willing to admit that a non-recursive build system is, simply put, more efficient.
For instance, you could look at xine-lib’s build system, and note that I never made it non-recursive: the problem there was that my fellow Darren didn’t like the idea to separate the sources from their output result, so it kept recursive.
Last summer instead I worked on an util-linux branch that caused it to go almost entirely non-recursive, which made it blazing fast to build; unfortunately my original approach was stylistically bad, and indeed I could see the issues. Unfortunately, while I did intend rebasing the patchset solving the issues found with it, it was a time-consuming task, and I hadn’t had the time to work on it.
In other cases, a fully non-recursive build system is impractical simply because it relies on tools that were designed with recursive makefiles in mind, which is the case both for tools like gettext, and gtk-doc. Which is why udev – whose buildsystem I worked on a bit of time ago – still has recursive Makefile.am files for the two gtk-doc outputs: there is just no way to get gtk-doc to work fine with non-recursive Makefiles — and for what it’s worth, it also works badly with out-of-tree builds. Sigh!
What probably makes me the saddest, is that there are build systems designed to work just and only recursive; under the idea that you can do the same type of work, with the same efficiency, in less lines of code or with a much less complex software.. and most of those suck at parallel building, which makes them very inefficient for the single task. In this context, I understand and relate to Matthew’s post about people deciding that something is “too bloated” and just rewrite it from scratch to produce a vastly sub-optimal result — I think I made the same point about CMake before.
And this is not to say that there isn’t always space for improvements, and that less code can be more efficient, if you reuse libraries and apply other tricks — I’m just saying that you should be always wary of software, and build systems, suggesting simplicity, efficiency and features at the same time: recursive is sure easy to provide, but it’s far from efficient. And an efficient build system would require to know enough trickeries to pack up the dependency resolution to compress the timing. And all of this was without taking into consideration the issue of distributed build, where you can run in parallel a high number of compile tasks, but no more than a few linking or generating tasks.
Of course, one could argue Gustafson’s law and assert that rather than building a single package fast, people would want to build more packages at the same time, which is what emerge --jobs option is designed to do, and what ChromiumOS build system implements with the parallel_emerge script. But this only covers full-system builds and upgrades, while build systems should equally targeted to make a single-package build fast enough to not cause the developers to waste time.
At least I hope now it is clear why recursive build system simply suck for parallelism.
I guess you know about waf (there is a eclass about it in portage tree).http://code.google.com/p/waf/It does parallel build and even has an option to visualize what’s done, more or less the way you’ve described here.check http://waf.googlecode.com/s…
I do agree, recursive Makefiles is just an excuse for a lazy ( incompetent ) developer.However, me and a friend had some discussions about how to use make, we decided that we should find one buildsystem each and make it do the same work as a given Makefile. I choose cmake and even though the syntax is horrible ( and reminds me of windows in some way ), it was very easy to get the same features, and I think I got parallell make for free…
Andreas, cmake gives you more or less the same features you get from autoconf+automake+libtool.. well a bit less and a bit more depending on how you look into it, with a very terrible syntax (which only a fanboy would say is better than any one other syntax I have ever seen).It is more compact, since it requires less software, but nothing especially new. If you need to do something particularly sophisticated, it is a mess to implement on CMake just as much as it is with classic make.
waf is really good, you can use it as recursive build system and it is very good at parallel builds. it even allows you to avoid such situations:https://waf.googlecode.com/…replacing them with:https://waf.googlecode.com/…It first runs all the nested wscripts and generates tasklist and then executes tasks from that list in parallel
Maybe this might interest you.http://esr.ibiblio.org/?p=3108
I recently put together a (very) small package using Autotools, and thought I could use a non-recursive build, since I was already building the software with a single Makefile.I fought Autotools for a day or so, and then went back to a recursive build to handle sources, docs, etc. in turn. There probably is a way to get Autotools to handle an non-recursive install, but it isn’t easy or obvious.Will
If your package is public, let me see it and I’ll tell you what you need to do to make it work, basically.I converted the other day xf86-input-synaptics, which is now non-recursive upstream.
If you want to have fun some day and a lot of time, then try out ghostscript with “make -j”… It may not fail the first time, but sooner or later it will. They have done their own system, some sort of non-recursive buildsystem, where they ave loads of *.mak imported into Makefile depending on your configuration. Their problem? Loads and loads of variables, and the ordering of them…They are very found of doing things likefoorbar : $(foo_h)foo_h=$(bar_h)and since foo_h is not defined until after foobar then make prints a warning if you do “make –warn-undefined-variables”. And this seems to lead to that if you look at the makefile target per target, then the deps are correct, however make fails to resolv them leading to funkyness. And it is a shame, because when the make process does not fail parallell takes less then half the time here, and I guess even less if sometings was made so it did not remake targets.
Nice writeup! Not only is recursive make hard on performance, but it makes it harder to ensure correct builds, at least with most variants of make.Your diagrams really caught my eye, because they remind me very much of the build visualization in ElectricInsight ( “example”: http://i.imgur.com/lK5Om.png , “more info”:http://electric-cloud.com/p… ).Also, you might be interested to know that “ElectricMake”:http://electric-cloud.com/p… has some cool technology that automatically and safely consolidates recursive makes, so you get the performance benefits without necessarily having to restructure your build. (Disclaimer: I’m the lead developer for both of those tools)
Hey Diego, I recently wrote an article called “Fixing recursive make” (http://blog.melski.net/2012… that goes into some detail about how Electric Make solves the problems with recursive make. Thought you might find it interesting.