I’m sorry it took so long but I had more stuff to write about in the mean time, and I’m really posting stuff as it comes with some pretty randomly ordered things.
In the post about the Portage Tree size I blandly and incompletely separate the overhead due to the filesystem block allocation from the rest of size of the components themselves. Since the whole data was gathered a night I was bored and trying to fixing up my kernel to have both Radeon’s KMS and the Atheros drivers working, it really didn’t strike as a complete work, and indeed it was just to give some sense of proportion on what is actually using up the space (and as you might have noticed, almost all people involved do find the size, and amount, of ChangeLogs a problem). Robin then asked for some more interesting statistics to look at, in particular the trend of the overhead depending on the size of the filesystem blocks.
This post, which comes after quite some angst is going to illustrate the results, although they do tend to be quite easy to see with the involved graphs. I hope this time the graphs do work for everybody out of the box; last time I used Google Docs to produce the output and linked it directly, this saved a lot of traffic on my side, but didn’t work for everybody. This time I’m going to use my blog’s server to publish all the results, hoping it won’t create any stir on it…
First of all, the data; I’m going to publish all the data I collected here, so that you can make use of it in any way you’d like; please note that it might not be perfect, knowledge about filesystems isn’t my favourite subject, so while it should be pretty consistent, there might be side-effects I didn’t consider; for instance, I’m not sure on whether directories have always the same size, and whether that size is the same for any filesystem out there; I assume both of these to be truths, so if I did any mistake you might have to adapt a bit the data.
I also hasn’t gone considering the amount of inodes used for each different configuration, and this is because I really don’t know for certainty how that behaves, and how to find how much space is used by the filesystem structures that handle inodes’ and files’ data. If somebody with better knowledge of that can get me some data, I might be able to improve the results. I’m afraid this is actually pretty critical to have a proper comparison of efficiency between differently-sized blocks because, well, the smaller the block the more blocks you need, and if you need more blocks, you end up with more data associated to that. So if you know more about filesystems than me and want to suggest how to improve this, I’ll be grateful.
I’m attaching the original spreadsheet as well as the tweaked charts (and the PDF of them for those not having OpenOffice at hand).
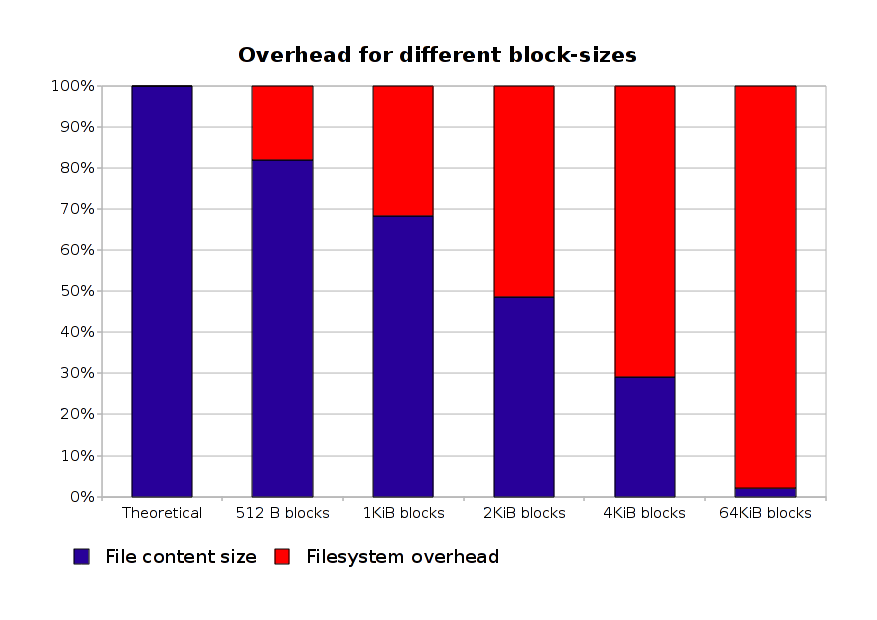
This first graph should give an idea about the storage efficiency of the Gentoo tree changes depending on the size block size: on the far left you got the theoretical point: 100% efficiency, where only the actual files that are in the tree are stored; on the far right an extreme case, a filesystem with 64KiB blocks… for those who wonder, the only way I found to actually have such a filesystem working on Linux is using HFS+ (which is actually interesting to know, I should probably put in such a filesystem the video files I have…); while XFS supports that in the specs, the Linux implementation doesn’t: it only supports blocks of the same size of a page, or smaller (so less than or equal to 4KiB) — I’m not sure why that’s the case, it seems kinda silly since at least HFS+ seems to work fine with bigger sizes.
With the “default” size of 4KiB (page size) the efficiency of the tree seems to be definitely reduced: it goes down to 30%, which is really not good. This really should suggest everybody who care about storage efficiency to move to 1KiB blocks for the Portage tree (and most likely, not just that).
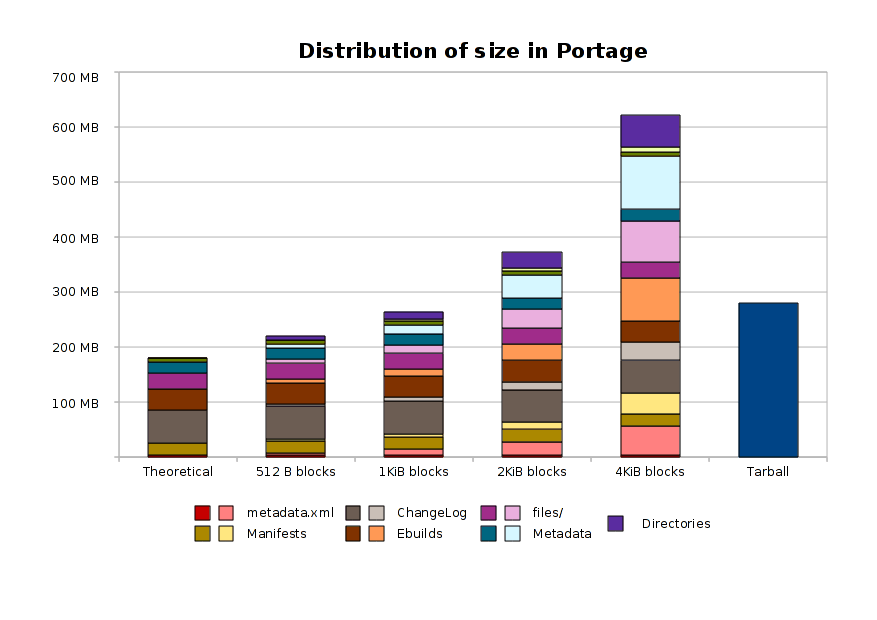
This instead should show you how the data inside the tree is distributed; note that I dropped the 64KiB-blocks case, this because the graph would have been unreadable: on such a filesystem, the grand total amounts of just a bit shy of 9GB. This is also why I didn’t go one step further and simulated all the various filesystems to compare the actual used/free space in them, and in the number of inodes.
*This is actually interesting, the fact that I wanted to comment on the chart, not leaving them to speak for themselves, let me find out that I did a huge mistake and was charting the complete size and the overhead instead of the theoretical size and the overhead in this chart. But it also says that it’s easier to note these things in graphical form rather than just looking at the numbers.*
So how do we interpret this data? Well, first of all, as I said, on a 4KiB-sized filesystem, Portage is pretty inefficient: there are too many small files: here the problem is not with ChangeLog (who still has a non-trivial overhead), but rather with the metadata.xml files (most of them are quite small), the ebuilds themselves, and the support files (patches, config files, and so on). The highest offender of overhead in such a configuration is, though, the generated portage metadata: the files are very small, and I don’t think any of them is using more than one block. We also have a huge amount of directories.
Now, the obvious solution to this kind of problems, is, quite reasonably actually, using smaller block sizes. From the reliability chart you can see already that without going for the very-efficient 512 bytes blocks size (which might starve at inode numbers), 1 KiB blocks size yields a 70% efficiency, which is not bad, after all, for a compromise. On the other hand, there is one problem with accepting that as the main approach: the default for almost all filesystems is 4KiB blocks (and actually, I think that for modern filesystems that’s also quite a bad choice, since most of the files that a normal desktop user would be handling nowadays are much bigger, which means that maybe even 128KiB blocks would prove much efficient), so if there is anything we can do to reduce the overhead for that case, without hindering the performance on 512 bytes-sized blocks, I think we should look into it.
As other have said, “throwing more disks at it” is not always the proper solution (mostly because while you can easily find how to add more disk space, it’s hard to get reliable disk space. I just added two external WD disks to have a two-level backup for my data…
So comments, ideas about what to try, ideas about how to make the data gathering more accurate and so on are definitely welcome! And so are links to this post on sites like Reddit which seems to have happened in the past few days, judging from the traffic on my webserver.