Flameeyes's Weblog
This Time Self-Hosted
dark mode
light mode
Search
Flameeyes's Weblog
Search
Search
Popular tags
Gentoo
xine
Ruby
KDE
Security
Peregrinazioni Mentali
Tinderbox
FreeBSD
Hardware
QA
The Latest
View All
2025-02-16
3 comments
Whirlpool AP330W: It’s A Trap
2025-02-02
No comments
Hardware Review: Ozlo Sleepbuds
2025-01-19
No comments
From Furniture Websites To Sweet Home 3D
2025-01-05
3 comments
So, Could We Get Open Source Washing Machines?
Browsing Tag
portage
59 posts
English
Technical
2009-12-12
Bigger, better tinderbox
Flameeyes
English
Technical
2009-12-06
Opening up the tinderbox
Flameeyes
English
Technical
2009-12-05
Why the tinderbox is a non-distributed effort
Flameeyes
English
Technical
2009-12-02
Needing a run control
Flameeyes
English
Technical
2009-11-26
What the tinderbox is doing for you
Flameeyes
English
Technical
2009-11-24
More tinderbox notes, just to say
Flameeyes
English
Technical
2009-11-22
Tinderbox: explaining some works
Flameeyes
English
Technical
2009-10-12
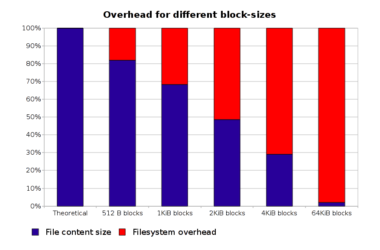
And finally, the Portage Tree overhead data
Flameeyes
English
Technical
2009-09-28
The size of the Gentoo tree
Flameeyes
English
Technical
2009-09-09
Proper dependencies aren’t overcomplex
Flameeyes