
My tinderbox for those who don’t know it, is a semi-automatic continuous integration testing tool. What it does is testing, repeatedly and continuously, the ebuilds in tree to identify failures and breakages in them as soon as they are available. The original scope of the testing was ensuring that the tree could be ready for using --as-needed by default – it became a default a few months ago – but since then it has expanded to a number of other testing conditions.
Last time I wrote about it, I was going to start reporting bugs related to detected overflows and so I did; afterwards there has been two special requests for testing, from the Qt team for the 4.7 version, and from the GNOME team for the GTK 2.22 release — explicitly to avoid my rants as it happens. This latter actually became a full-sweep tinderbox run, since there are just too many packages using GTK in tree.
Now, I already said before that running the tinderbox takes a lot of time, and thankfully, Zac and Kevin are making my task there much easier; on the other hand, right now I start to have trouble running it mostly for a pure economical matter. From one side, running it 24⁄7 for the past years starts to take its tall in power bills, from another, I start to need Yamato’s power to complete some job tasks, and in that time, the tinderbox is slowing down or pausing altogether. This, in turn, causes the tinderbox to go quite off-sync with the rest of Gentoo and requires even more time from there on.
But there are a few more problems that are not just money-related; one is that that the reason why I stopped posting regular updates about the tinderbox itself and its development is that I’ve been asked by one developer not to write about it, as he didn’t feel right I was asking for help with it publicly — but as it turns out, I really cannot keep doing it this way so I have to choose between asking for help or stop running the tinderbox at all. It also doesn’t help that very few developers seem to find the tinderbox useful for what it does: only a few people actually ask me to execute it for their packages when a new version is out, and as I said the GNOME team only seemed compelled to ask me about it for the sole reason of avoiding another rant from me rather than actually to identify and solve the related problems.
Not all users seem to be happy with the results, either. Since running the tinderbox also means finding packages that are broken, or that appear so, which usually end up being last-rited and scheduled for removal, it can upset users of those packages, whether they really need them or they just pretend and are tied to them just for legacy or historical reasons. Luckily, I found how to turn this to my advantage, which is more or less what I did already with webmin sometime ago and that is to suggest users to eitehr pick up the package themselves or, in alternative, to hire someone to fix it up and get it up to speed with QA practices. Up to now I hadn’t been hired to do that, but at least both webmin and nmh seem to have gotten a proxy-maintainer to deal with them.
Talking about problems, the current workflow with the tinderbox is a very bad compromise; since auto-filing bugs is a bit troublesome, I haven’t gone around filing them just yet; Kevin provided me with some scripts I’d have to try, but they have one issue, which is the actual reason why I haven’t gone filing them just yet: I skim through the tinderbox build logs through a grep process running within an emacs session; I check log by log for bugs I already reported (that I can remember); I check Bugzilla through Firefox in the background (it’s one of the few uses of Firefox I still have; otherwise I mostly migrated to Chromium months ago) to see if someone else reported the same bug, then if all fails, I manually file it through the use of templates.
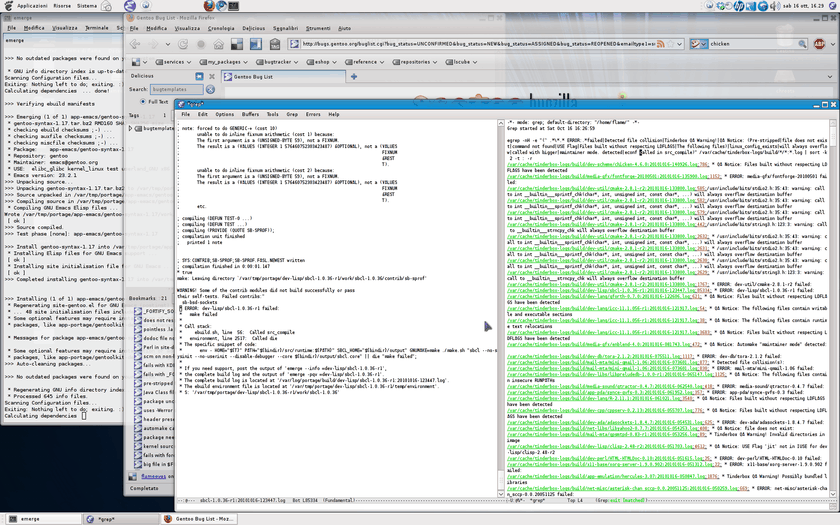
This works out relatively well for a long series of “coincidences”: the logs are available to be read as my user, and Emacs can show me a browsable report of a grep; Bugzilla allows you to have a direct search query in Firefox search, and most of the time, the full build log is enough to report the bug. Unfortunately it has a number of shortcomings, for instance for emerge --info I have to manually copy and paste it from a screen terminal (also running on the same desktop in the background).
To actually add a self-reporting script to the workflow, what I’d be looking for is a way to launch it from within Emacs itself, picking out the package name and the maintainers from the log file itself (portage reports maintainer information at the top of the log nowadays, one thing that Zac implemented and made me very happy about). Another thing that would help would be bugzilla integration with Emacs to find the bugs; this may actually be something a Gentoo user who’s well versed in Emacs could help a lot about; adding a command “search on Gentoo Bugzilla” to Emacs so that it identifies the package the build log refers to, or the ebuild refers to, and report within itself the list of known open bugs for that package. I’m sure other developers using Emacs would find that very useful.
I also tried using another feature that Zac implemented, to my delight: compressed logs; having gzip-compressed logs makes the whole process faster for the tinderbox (logs are definitely smaller on disk, and thus require less I/O), and makes it easier to store older data, but unfortunately Bugzilla does not hand out transparently those logs to browsers; worse, it seems to double-compress them with Firefox even though they are properly provided a mime-type declaration, resulting in difficult-to-grok logs (I still have to compress some logs because they are just too big to be uploaded to Bugzilla). This is very unfortunate because scarabeus asked me before if I could get the full logs available somewhere; serving them not compressed is not going to be fun for any hosting service. Maybe Amazon S3 could turn out useful here.
Actually, there is also one feature that the tinderbox lost, as of lately: the flameeyestinderbox user on identi.ca, which logged, as a bot, all the running of the tinderbox, was banned again. The first time support unbanned it the same day, this time I didn’t even ask. An average of around 700 messages a day, and a single follower (me) probably don’t make it very palatable to the identi.ca admins. Jürgen suggested me to try requesting my own private StatusNet, but I’m not really sure I want to ask them to store even more of my data, it’s unlikely to be of any use for them. Maybe if I’ll ever end up having to coordinate more than one tinderbox instance, I’ll set up a StatusNet installation proper and let that one aggregate all the tinderboxes reporting their issues. Until a new solution has been found, I then fully disabled bti in the tinderbox code.
Anyway, if you wish to help, feel free to leave comments with ideas, or discuss them on the gentoo-qa mailing list (Kevin, you too please, your mail ended up in my TODO queue, and lately I just don’t have time to go through that queue often enough, sigh!); help with log analysis, bug opening and CCing is all going to make running the tinderbox much smoother. And that’s going to be needed if I won’t be able to run it 24⁄7. As for running the tinderbox for longer, if you run a company and you find the tinderbox worth it, you can decide to hire me to keep it running or donate/provide access to boxes powerful enough to run another instance of it. You can even set up your own (but it might get tricky to handle, especially bug reporting since if you’re not a Gentoo developer nor a power user with editbugs capabilities you cannot directly assign the filed bugs).
All help is appreciated, once again. Please don’t leave me here alone though…
What would be the storage requirements for the tinderbox logs:Length of time a log is supposed to be available?Size of the Logs?Amount of bandwidth needed?I have some spare bandwidth and disk space on my web server I could donate if it what I have extra will fit with those requirements.
A combination of about all of those; uncompressed, the logs for the past week are 317MB; they are highly reduced once compressed, but as I said that is hardly handy with Bugzilla.Also, very often a week is not long enough, as it has happened before that some developer asked me for the b uild log of one of the dependencies, to know how it has been installed; it’s a proper request but it requires a much longer history because the dependencies might have been merged many weeks before.Even assuming a 1:10 ratio of compression, and about a gigabyte of logs to be storable (which I could do myself), the number of requests for logs are likely going to be troublesome (and this is also considering disallowing robots through the exclusion protocol _and_ using “my ModSecurity ruleset”:https://www.flameeyes.eu/pr… since not all robots abide or are filtered by it).
A combination of thoughts and ideas come to mind.First, on the subject of not having enough CPU cycles, there’s a very wide variety of services available from Amazon. One’s I’m aware of:* Straight-uptime VPS (like having a linode or Slicehost)* Scaled VPS (having more processes spawn as-needed. Potentially useful if you want to do low-latency integration testing across multiple configurations and USE flags, or maybe if you just want to try DistCC in a cloud.)* VPS with bids on uptime (so, for example, if you don’t want to pay more than X/hr for uptime…)* VPS options which charge for data storage and CPU uptime independently–if you’re not storing any data (and, apparently, the boot-time, reset-to VPS image doesn’t count), you only pay for uptime. You can still keep your data in another location that *does* persist.Note, I haven’t actually used any of these myself; I only attended a BarCamp session on EC2. I was thinking about the charge-for-uptime as part of an automated process, though…Second, on the subject of paying for all this, you could very probably get support from the commercial maintainers of some of the packages. The folks behind Qt, Gtk, PHP et al might be willing to subsidize integration-testing other software if it means getting testing up-to-date testing reports. Toolkit and library writers might also find statistics on bug frequency wrt usage of their APIs valuable. Google might do it simply for the benefit of a cleaner and more-generally-secure open-source codebase.Third, on the subject of identi.ca…I haven’t been following that, but you might try CIA.vc. ESR set that up for gpsd’s regression tests. (http://esr.ibiblio.org/?p=1…Fourth, on the matter of your individual processing of results…How much of that could be crowdsourced? How much expert-level knowledge is required? I mean, say you had thirty people who were interested in helping? Or Amazon Mechanical Turk?Anyway, just throwing some ideas out there.
the logs really do take a lot of room uncompressed. gcc-4.4.5 was over 13+MB uncompressedwould like to see a formatted string in the QA output that could be awked or grepped for that would report warning level and type, package-name and versionOf course the QA string itself works to some degree when just searching the build logs but nice to have it all on one line.A stable tree is a good thing. Thanks for all your work.Will join mailing-list
Michael, I do have experience with EC2, and it’s the farthest I can think of something the tinderbox can make use of. Tinderbox really needs fast I/O (so most VPS solutions are no-go) beside CPU time; it really needs a dedicated server to run smoothly.I’m not sure how much the commercial vendors are interested in testing Gentoo; sometimes they really seem to only consider “the big guys” to be worth the effort of working with. Lately, even a few non-commercial projects seem to only care about Fedora/Ubuntu/Debian depending on their own targets.Having a more crowdsourced analysis of the logs would definitely help, but there has to be a way to provide a way to deal with those; a proper web interface to replace the grep I used above would probably help a lot. But as user99 points out, it would be much easier if regular strings were used all over it.For what it’s worth, I think the only service Amazon could provide that would be worth using with the tinderbox would be S3 for storage.
Ech. There’s no way to distribute this process? (i.e. set up a VMWare appliance app (or equivalent) to handle a subset of the work?)Anyway, regarding commercial vendors’ interest, my thought is that they may not be interested in testing Gentoo specifically, but they may be interested in getting bug statistics involving usage of their API; a broad bug incidence in software using a particular component may indicate that that component needs to be designed better in some fashion.Apart from that particular issue, upstream bugs manifest in Big Guy distros as well as Gentoo, so a broad integration testing system built on a rolling release system like Gentoo has the benefit of detecting upstream issues before more rhythmic-release systems like Red Hat see them.Finally, I don’t know how much of Gentoo could be chunked away like this, but when I was experimenting with different -j options for building ffmpeg, I put the source tree in tmpfs to remove I/O from being a bottleneck. That wouldn’t work for all packages, of course. (It would be interesting to see build-time storage requirement deltas for various packages, but that’s just me grasping at straws.)
Michael, I covered “why the tinderbox can’t be distributed”:https://blog.flameeyes.eu/2… last year — no there is no real way to change this, it’s unfortunate, but that’s about it.As for building in tmpfs, I’m now coming up with a much simpler way to handle that, but there are catches there as well; with 16GB of RAM I can do _most_ (not all of course) builds in RAM, but then I’d have to remove the temporary work directory even if the build failed. This makes it impossible to diagnose problems that require access to logs that are not saved on the build log by default (i.e. the @config.log@ from autoconf builds).
I have access to some beefy hardware (four quad core Xeon cpus, 48G RAM, 80G SSD) at the place I’m working. However there are a few constraints (access) that I need to be careful. I’m willing to donate my time as well. I’ve being using Gentoo since 2003 and administer 4-5 servers. I’ve been thinking of contacting you to make use of that hardware for tinderboxing and this post prompted me. Will be happy to talk over email on ways I can help.PS: Although I haven’t posted any comments before this, I read your blog often.
It is improving the overall quality of gentoo, defenatly. If people want to use it for their packages or not, I would not really care about. Since the general sweeps still uncover problems.So defenatly a thumbsup from my side.About removed packages that upset users… we could create a ‘staging/tainted’ overlay for packages that break other things. It would indicate that these packages have problems but under some circumstances still can be installed for those who want to.Ofcourse it would be nice if portage handled overlays more easily, e.g. supporting selecting an overlay for a package.Anyways, thanks for all your work.
I’m fairly sure that most are experiencing at least better behavior from xscreensaver at least from those of you who use it.netpbm bug (337747) is xscreensaver and mine has definitely been better. 😉